
To be independent of externally hosted video conferencing tools, such as MS Teams, Google Meet, Zoom and others, I've installed a Jitsi video conference server a few years ago. Besides having full control over the server and its resources, I and my clients (I do offer consulting services, too) can be sure that the conversation is not registered on any third party (cloud) server and all (temporary) data is stored in Switzerland on my own environment.
This setup, behind a NAT and an internal Reverse Proxy (Nginx), has been working very well in the past - until Jitsi was updated a few months ago. Since then I ran into weird connectivity and video issues previously not seen.
One of the new issues was that external users were not able to join the video call. While devices in the internal LAN were able to correctly join the conference call, external users coming from the Internet were not able to join. To make this even more interesting: When a remote participant wanted to join the call, everybody was kicked off the meeting (disconnected), even the internal devices.
The logs of the jitsi-videobridge (jvb) showed such entries:
root@jitsi:/var/log/jitsi# tail -f jvb.log
JVB 2023-10-31 08:16:42.382 SEVERE: [30] HealthChecker.run#181: Health check failed in PT0.000014S: Result(success=false, hardFailure=true, responseCode=null, sticky=false, message=Address discovery through STUN failed)
JVB 2023-10-31 08:17:42.382 SEVERE: [30] HealthChecker.run#181: Health check failed in PT0.000012S: Result(success=false, hardFailure=true, responseCode=null, sticky=false, message=Address discovery through STUN failed)
At the same time Kernel log entries showed the firewall rejected an outgoing connection from Jitsi (SRC) to the remote participant (DST) on port UDP/443.
According to a comment in issue #1165 on GitHub, UDP/443 outgoing (to any) is now required for Jitsi, followed by a restart of jitsi-videobridge.
But after this additional outgoing firewall rule was added, yet another annoying error showed up.
Once the problem with the remote participant join was fixed, the video conference still did not work. Instead a warning pop up showed up in the bottom left part of the screen, indicating a problem with the communication to the video bridge:
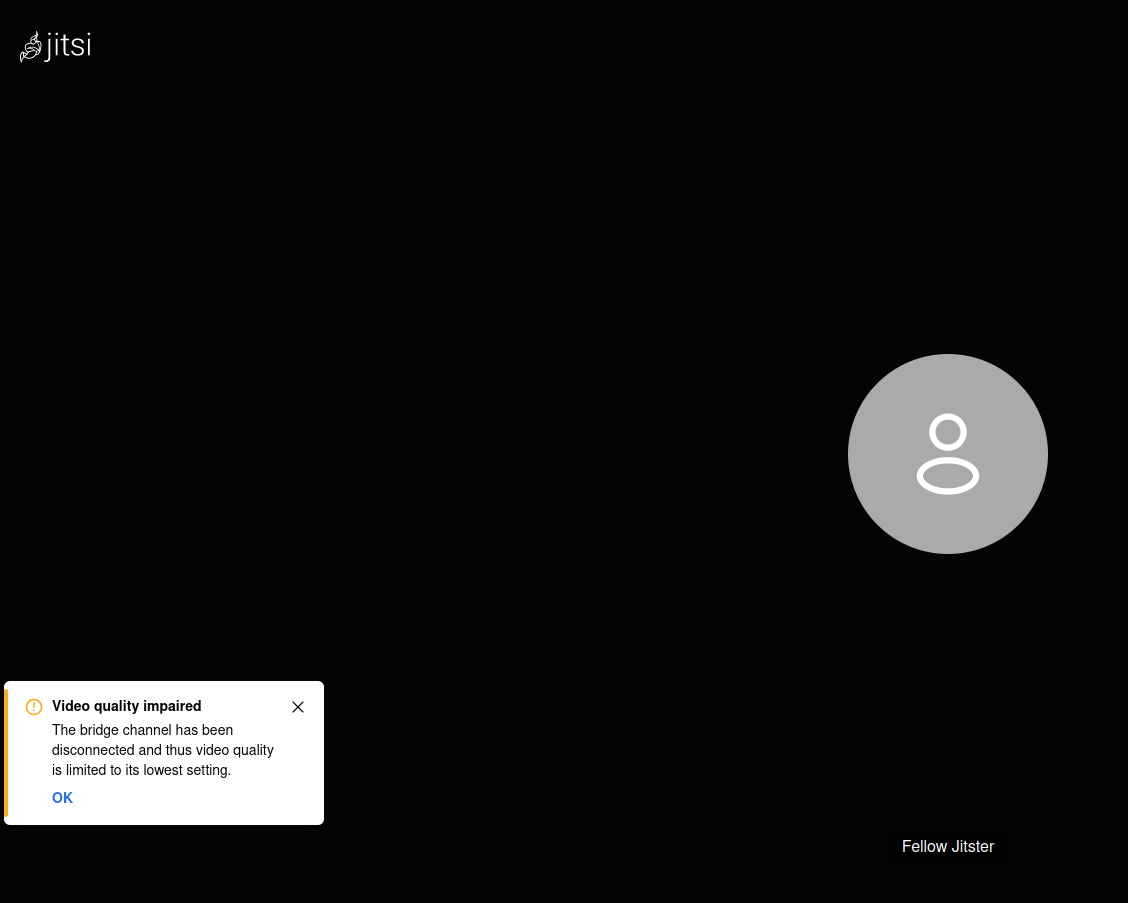
The information showed the following warning:
Video quality impaired
The bridge channel has been disconnected and thus video quality is limited to its lowest setting.
However video (and audio!) did not work at all - it was not just limited to lower settings.
The Jitsi log in this situation was pointing to a failed connection back to the client:
JVB 2024-03-28 13:10:38.048 INFO: [99] [confId=77ad92d64b80315 conf_name=test@conference.meet.example.com meeting_id=977a6475 epId=4de9e2aa stats_id=Oleta-sYL local_ufrag=2tnje1hq2itsb9 ufrag=2tnje1hq2itsb9] ConnectivityCheckClient.processTimeout#881: timeout for pair: 192.168.1.190:10000/udp/host -> 172.16.238.1:32887/udp/prflx (stream-4de9e2aa.RTP), failing.
JVB 2024-03-28 13:10:38.070 INFO: [99] [confId=77ad92d64b80315 conf_name=test@conference.meet.example.com meeting_id=977a6475 epId=4de9e2aa stats_id=Oleta-sYL local_ufrag=2tnje1hq2itsb9 ufrag=2tnje1hq2itsb9] ConnectivityCheckClient.processTimeout#881: timeout for pair: 192.168.1.190:10000/udp/host -> 192.168.187.1:49514/udp/prflx (stream-4de9e2aa.RTP), failing.
JVB 2024-03-28 13:10:44.680 INFO: [97] [confId=77ad92d64b80315 conf_name=test@conference.meet.example.com meeting_id=977a6475] Conference.recentSpeakersChanged#475: Recent speakers changed: [4de9e2aa, 2853e836], dominant speaker changed: true silence:false
I tried all kinds of hints, from reinstalling Jitsi to using a newer prosody version to reconfigure Jitsi from scratch, but nothing helped.
At last I came across a very important hint, that recent Jitsi versions now use web socket connections, which require changes in the reverse proxy setup.
With all these problems and also the fact that there seems to be updated firewall requirements, I decided to re-create the firewall rules (port forwardings) and reverse proxy config from scratch.
So let's start from scratch - network wise.
I did not touch the existing Jitsi configuration, which I adjusted to use prosody authentication. The installed Jitsi packages on the Jitsi server (Debian Bookworm) are currently at the newest version anyway:
root@jitsi:/# dpkg -l |grep jitsi
ii jitsi-meet 2.0.9364-1 all WebRTC JavaScript video conferences
ii jitsi-meet-prosody 1.0.7874-1 all Prosody configuration for Jitsi Meet
ii jitsi-meet-turnserver 1.0.7874-1 all Configures coturn to be used with Jitsi Meet
ii jitsi-meet-web 1.0.7874-1 all WebRTC JavaScript video conferences
ii jitsi-meet-web-config 1.0.7874-1 all Configuration for web serving of Jitsi Meet
ii jitsi-videobridge2 2.3-92-g64f9f34f-1 all WebRTC compatible Selective Forwarding Unit (SFU)
ii lua-basexx 0.4.1-jitsi1 all baseXX encoding/decoding library for Lua
ii lua-cjson:amd64 2.1.0.10-jitsi1 amd64 JSON parser/encoder for Lua
The following system architecture drawing should be helpful information how my Jitsi setup looks like:
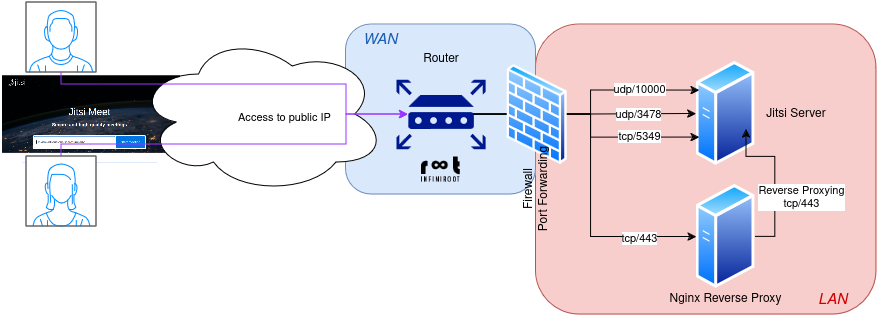
There are two very important parts of this setup:
The firewall (either on your router or on a separate device) handles the incoming connections and must forward specific ports to the Jitsi server in the internal LAN. The following ports need to be forwarded:
As mentioned above, Jitsi now seems to use web sockets for the video call (since when exactly I was not able to find out). The Nginx configuration on the reverse proxy was adjusted accordingly:
root@reverseproxy ~ # cat /etc/nginx/sites-enabled/meet.example.com.conf
###########################
# meet.example.com
###########################
server {
listen 443 ssl http2;
server_name meet.example.com;
access_log /var/log/nginx/meet.example.com.access.log;
error_log /var/log/nginx/meet.example.com.error.log;
# [...] ssl settings and stuff [...]
location / {
include /etc/nginx/proxy.conf;
proxy_set_header X-Forwarded-Proto https;
proxy_pass https://192.168.1.190; # internal IP of Jitsi server
}
location /xmpp-websocket {
proxy_pass https://192.168.1.190;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
}
location /colibri-ws {
proxy_pass https://192.168.1.190;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
}
}
After applying the new reverse proxy configuration, the error with the "impaired video quality" disappeared!
To sum this up, the following network configurations were adjusted or verified:
Once these configs were corrected/verified and Jitsi restarted, video conference calls started working again with both internal and remote devices (tested here with desktop computer and smartphone connected to 5G). Hurray!

AWS Android Ansible Apache Apple Atlassian BSD Backup Bash Bluecoat CMS Chef Cloud Coding Consul Containers CouchDB DB DNS Database Databases Docker ELK Elasticsearch Filebeat FreeBSD Galera Git GlusterFS Grafana Graphics HAProxy HTML Hacks Hardware Icinga Icingaweb Icingaweb2 Influx Internet Java KVM Kibana Kodi Kubernetes LVM LXC Linux Logstash Mac Macintosh Mail MariaDB Minio MongoDB Monitoring Multimedia MySQL NFS Nagios Network Nginx OSSEC OTRS Office PGSQL PHP Perl Personal PostgreSQL Postgres PowerDNS Proxmox Proxy Python Rancher Rant Redis Roundcube SSL Samba Seafile Security Shell SmartOS Solaris Surveillance Systemd TLS Tomcat Ubuntu Unix VMWare VMware Varnish Virtualization Windows Wireless Wordpress Wyse ZFS Zoneminder