
Yesterday our ELK's ElasticSearch ran out of disk space and stopped working. After I deleted some older indexes and even grew the file system a bit, the ElasticSearch cluster status still showed red:
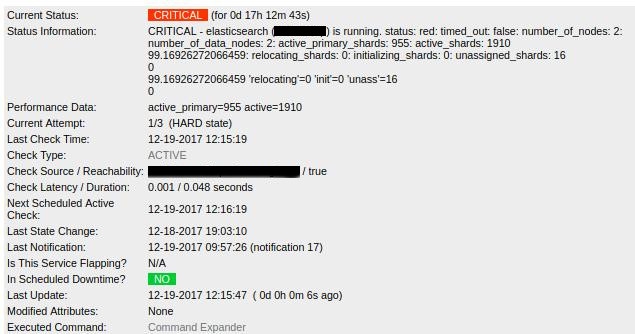
But why? To make sure all shards are being handled correctly, I restarted one ES node and let it assign and re-index all the indexes. But it got stuck with 16 shards being left unassigned.
That's when I realized something's off and I found these two blog articles which helped me understand what's going on:
I manually verified about such shards being left unassigned:
claudio@tux ~ $ curl -q -s "http://es01.example.com:9200/_cat/shards" | egrep "(UNASSIGNED|INIT)"
docker-2017.12.18 1 p UNASSIGNED
docker-2017.12.18 1 r UNASSIGNED
docker-2017.12.18 3 p UNASSIGNED
docker-2017.12.18 3 r UNASSIGNED
docker-2017.12.18 0 p UNASSIGNED
docker-2017.12.18 0 r UNASSIGNED
filebeat-2017.12.18 4 p UNASSIGNED
filebeat-2017.12.18 4 r UNASSIGNED
application-2017.12.18 4 p UNASSIGNED
application-2017.12.18 4 r UNASSIGNED
application-2017.12.18 0 p UNASSIGNED
application-2017.12.18 0 r UNASSIGNED
logstash-2017.12.18 1 p UNASSIGNED
logstash-2017.12.18 1 r UNASSIGNED
logstash-2017.12.18 0 p UNASSIGNED
logstash-2017.12.18 0 r UNASSIGNED
Yep, here they are. A total of 16 shards (as mentioned by the monitoring) were not assigned.
I followed the hint of the articles above, however the syntax has changed since. Both articles describe the "allocate" command. But in ElasticSearch 6.x this command does not exist anymore.
Instead there are now two commands, one for a primary shard, one for a replica shard. From the documentation (https://www.elastic.co/guide/en/elasticsearch/reference/current/cluster-reroute.html):
allocate_replica
Allocate an unassigned replica shard to a node. Accepts the index and shard for index name and shard number, and node to allocate the shard to. Takes allocation deciders into account.
As a manual override, two commands to forcefully allocate primary shards are available:
allocate_stale_primary
Allocate a primary shard to a node that holds a stale copy. Accepts the index and shard for index name and shard number, and node to allocate the shard to. Using this command may lead to data loss for the provided shard id. If a node which has the good copy of the data rejoins the cluster later on, that data will be overwritten with the data of the stale copy that was forcefully allocated with this command. To ensure that these implications are well-understood, this command requires the special field accept_data_loss to be explicitly set to true for it to work.
allocate_empty_primary
Allocate an empty primary shard to a node. Accepts the index and shard for index name and shard number, and node to allocate the shard to. Using this command leads to a complete loss of all data that was indexed into this shard, if it was previously started. If a node which has a copy of the data rejoins the cluster later on, that data will be deleted! To ensure that these implications are well-understood, this command requires the special field accept_data_loss to be explicitly set to true for it to work.
So I created the following command to parse all unassigned shards and run the corresponding allocate command - depending whether the shards are primary or replica shards (with echo in front of the curl command, to visually verify the command uses the correct variable values):
claudio@tux ~ $ curl -q -s "http://es01.example.com:9200/_cat/shards" | egrep "UNASSIGNED" | while read index shard type state; do if [ $type = "r" ]; then echo curl -H "Content-Type: application/json" -X POST "http://es01.example.com:9200/_cluster/reroute" -d "{ \"commands\" : [ { \"allocate_replica\": { \"index\": \"$index\", \"shard\": $shard, \"node\": \"es01\" } } ] }"; elif [ $type = "p" ]; then echo curl -H "Content-Type: application/json" -X POST "http://es01.example.com:9200/_cluster/reroute" -d "{ \"commands\" : [ { \"allocate_stale_primary\": { \"index\": \"$index\", \"shard\": $shard, \"node\": \"es02\", \"accept_data_loss\": true } } ] }"; fi; done
curl -X POST http://es01.example.com:9200/_cluster/reroute -d { "commands" : [ { "allocate_stale_primary": { "index": "docker-2017.12.18", "shard": 1, "node": "es02", "accept_data_loss": true } } ] }
curl -X POST http://es01.example.com:9200/_cluster/reroute -d { "commands" : [ { "allocate_replica": { "index": "docker-2017.12.18", "shard": 1, "node": "es01" } } ] }
curl -X POST http://es01.example.com:9200/_cluster/reroute -d { "commands" : [ { "allocate_stale_primary": { "index": "docker-2017.12.18", "shard": 3, "node": "es02", "accept_data_loss": true } } ] }
curl -X POST http://es01.example.com:9200/_cluster/reroute -d { "commands" : [ { "allocate_replica": { "index": "docker-2017.12.18", "shard": 3, "node": "es01" } } ] }
curl -X POST http://es01.example.com:9200/_cluster/reroute -d { "commands" : [ { "allocate_stale_primary": { "index": "docker-2017.12.18", "shard": 0, "node": "es02", "accept_data_loss": true } } ] }
curl -X POST http://es01.example.com:9200/_cluster/reroute -d { "commands" : [ { "allocate_replica": { "index": "docker-2017.12.18", "shard": 0, "node": "es01" } } ] }
curl -X POST http://es01.example.com:9200/_cluster/reroute -d { "commands" : [ { "allocate_stale_primary": { "index": "filebeat-2017.12.18", "shard": 4, "node": "es02", "accept_data_loss": true } } ] }
curl -X POST http://es01.example.com:9200/_cluster/reroute -d { "commands" : [ { "allocate_replica": { "index": "filebeat-2017.12.18", "shard": 4, "node": "es01" } } ] }
curl -X POST http://es01.example.com:9200/_cluster/reroute -d { "commands" : [ { "allocate_stale_primary": { "index": "application-2017.12.18", "shard": 4, "node": "es02", "accept_data_loss": true } } ] }
curl -X POST http://es01.example.com:9200/_cluster/reroute -d { "commands" : [ { "allocate_replica": { "index": "application-2017.12.18", "shard": 4, "node": "es01" } } ] }
curl -X POST http://es01.example.com:9200/_cluster/reroute -d { "commands" : [ { "allocate_stale_primary": { "index": "application-2017.12.18", "shard": 0, "node": "es02", "accept_data_loss": true } } ] }
curl -X POST http://es01.example.com:9200/_cluster/reroute -d { "commands" : [ { "allocate_replica": { "index": "application-2017.12.18", "shard": 0, "node": "es01" } } ] }
curl -X POST http://es01.example.com:9200/_cluster/reroute -d { "commands" : [ { "allocate_stale_primary": { "index": "logstash-2017.12.18", "shard": 1, "node": "es02", "accept_data_loss": true } } ] }
curl -X POST http://es01.example.com:9200/_cluster/reroute -d { "commands" : [ { "allocate_replica": { "index": "logstash-2017.12.18", "shard": 1, "node": "es01" } } ] }
curl -X POST http://es01.example.com:9200/_cluster/reroute -d { "commands" : [ { "allocate_stale_primary": { "index": "logstash-2017.12.18", "shard": 0, "node": "es02", "accept_data_loss": true } } ] }
curl -X POST http://es01.example.com:9200/_cluster/reroute -d { "commands" : [ { "allocate_replica": { "index": "logstash-2017.12.18", "shard": 0, "node": "es01" } } ] }
But when I ran the command without the "echo", I got a ton of errors back. Taken a snippet from the huge error message:
"index":"logstash-2017.11.24","allocation_id":{"id":"eTNR1rY2TSqVhbzng-gTqA"}},{"state":"STARTED","primary":true,"node":"0o0eQXxcSJuWIFG2ohjwUg","relocating_node":null,"shard":2,"index":"logstash-2017.11.24","allocation_id":{"id":"v4BjD0FAR2SCbEWmWXv5QQ"}},{"state":"STARTED","primary":true,"node":"0o0eQXxcSJuWIFG2ohjwUg","relocating_node":null,"shard":4,"index":"logstash-2017.11.24","allocation_id":{"id":"L9uG4CIXS8-QAs8_0UAXWA"}},{"state":"STARTED","primary":true,"node":"0o0eQXxcSJuWIFG2ohjwUg","relocating_node":null,"shard":3,"index":"logstash-2017.11.24","allocation_id":{"id":"0xS1BcwSQpqn9JpjL6tJlg"}},{"state":"STARTED","primary":false,"node":"0o0eQXxcSJuWIFG2ohjwUg","relocating_node":null,"shard":0,"index":"logstash-2017.11.24","allocation_id":{"id":"QWO_lYpIRL6U8gSjTNL8pw"}}]}}}}{"error":{"root_cause":[{"type":"illegal_argument_exception","reason":"[allocate_replica] trying to allocate a replica shard [logstash-2017.12.18][0], while corresponding primary shard is still unassigned"}],"type":"illegal_argument_exception","reason":"[allocate_replica] trying to allocate a replica shard [logstash-2017.12.18][0], while corresponding primary shard is still unassigned"},"status":400}
The important part being:
trying to allocate a replica shard [logstash-2017.12.18][0], while corresponding primary shard is still unassigned
Makes sense. I tried to allocate a replica shard but obviously the primary shard needs to be allocated first. I changed the while loop to only run on primary shards:
claudio@tux ~ $ curl -q -s "http://es01.example.com:9200/_cat/shards" | egrep "UNASSIGNED" | while read index shard type state; do if [ $type = "p" ]; then curl -X POST "http://es01.example.com:9200/_cluster/reroute" -d "{ \"commands\" : [ { \"allocate_stale_primary\": { \"index\": \"$index\", \"shard\": $shard, \"node\": \"es01\", \"accept_data_loss\": true } } ] }"; fi; done
This time it seemed to work. I verified the unassigned shards again:
claudio@tux ~ $ curl -q -s "http://es01.example.com:9200/_cat/shards" | egrep "UNASSIGNED"
logstash-2017.12.18 0 r UNASSIGNED
filebeat-2017.12.19 1 r UNASSIGNED
filebeat-2017.12.19 3 r UNASSIGNED
docker-2017.12.18 3 r UNASSIGNED
application-2017.12.18 4 r UNASSIGNED
application-2017.12.18 0 r UNASSIGNED
Hey, much less now. And it seems that some of the replica shards were automatically assigned, too.
And now the curl command to force the allocation of the replica shards:
claudio@tux ~ $ curl -q -s "http://es01.example.com:9200/_cat/shards" | egrep "UNASSIGNED" | while read index shard type state; do if [ $type = "r" ]; then curl -X POST "http://es01.example.com:9200/_cluster/reroute" -d "{ \"commands\" : [ { \"allocate_replica\": { \"index\": \"$index\", \"shard\": $shard, \"node\": \"es02\" } } ] }"; fi; done
Note: I set data node es01 for primary shards and es02 for replica shards. You don't want to have both primary and replica shards on the same node. Don't forget about that.
I checked again about the current status and some of the allocated shards were now being re-indexed (but no unassigned shards were found anymore):
claudio@tux ~ $ curl -q -s "http://es01.example.com:9200/_cat/shards" | egrep "(UNASSIGNED|INIT)"
application-2017.12.18 4 r INITIALIZING 10.161.206.52 es02
application-2017.12.18 0 r INITIALIZING 10.161.206.52 es02
logstash-2017.12.18 1 r INITIALIZING 10.161.206.52 es02
logstash-2017.12.18 0 r INITIALIZING 10.161.206.52 es02
It took a couple of minutes until, eventually, all indexes were finished and cluster returned to green:
claudio@tux ~ $ curl -q -s "http://es01.example.com:9200/_cat/shards" | egrep "(UNASSIGNED|INIT)"; date
logstash-2017.12.18 0 r INITIALIZING 10.161.206.52 es02
Tue Dec 19 13:52:55 CET 2017
claudio@tux ~ $ curl -q -s "http://es01.example.com:9200/_cat/shards" | egrep "(UNASSIGNED|INIT)"; date
Tue Dec 19 13:54:50 CET 2017
claudio@tux ~ $
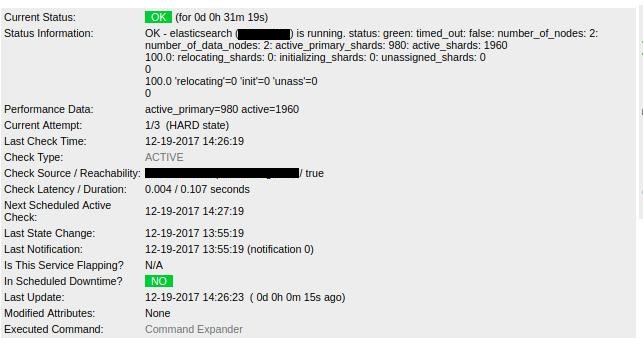
In case you get an error complaining about the Content-Type header:
{"error":"Content-Type header [application/x-www-form-urlencoded] is not supported","status":406}
Then add Content-Type: application/json to the curl command:
# curl -u elastic:secret -q -s "http://localhost:9200/_cat/shards" | egrep "UNASSIGNED" | while read index shard type state; do if [ $type = "r" ]; then curl -u elastic:secret -X POST -H "Content-Type: application/json" "http://localhost:9200/_cluster/reroute" -d "{ \"commands\" : [ { \"allocate_replica\": { \"index\": \"$index\", \"shard\": $shard, \"node\": \"es01\" } } ] }"; fi; done
In case you get the following error message:
reason: [NO(shard has exceeded the maximum number of retries [5] on failed allocation attempts - manually call [/_cluster/reroute?retry_failed=true] to retry
Then check out my follow-up article: Elasticsearch: Shards fail to allocate due to maximum number of retries exceeded.
It is also possible that the new allocation won't work, if the cluster members don't run on the same Elasticsearch version:
root@es01:~# curl -u elastic:secret -X POST -H "Content-Type: application/json" "http://localhost:9200/_cluster/reroute" -d "{ \"commands\" : [ { \"allocate_replica\": { \"index\": \"logstash-2019.09.07\", \"shard\": 0, \"node\": \"es02\" } } ] }"
{"error":{"root_cause":[{"type":"remote_transport_exception","reason":"[es02][192.168.100.102:9300][cluster:admin/reroute]"}],"type":"illegal_argument_exception","reason":"[allocate_replica] allocation of [logstash-2019.09.07][0] on node {es02}{t3GAvhY1SS2xZkt4U389jw}{68OF5vjFQzG2z-ynk4d0nw}{192.168.100.102}{192.168.100.102:9300}{ml.machine_memory=48535076864, xpack.installed=true, ml.max_open_jobs=20, ml.enabled=true} is not allowed, reason: [YES(shard has no previous failures)][YES(primary shard for this replica is already active)][YES(explicitly ignoring any disabling of allocation due to manual allocation commands via the reroute API)][NO(cannot allocate replica shard to a node with version [6.5.4] since this is older than the primary version [6.8.3])][YES(the shard is not being snapshotted)][YES(ignored as shard is not being recovered from a snapshot)][YES(node passes include/exclude/require filters)][YES(the shard does not exist on the same node)][YES(enough disk for shard on node, free: [3tb], shard size: [0b], free after allocating shard: [3tb])][YES(below shard recovery limit of outgoing: [0 < 2] incoming: [0 < 2])][YES(total shard limits are disabled: [index: -1, cluster: -1] <= 0)][YES(allocation awareness is not enabled, set cluster setting [cluster.routing.allocation.awareness.attributes] to enable it)]"},"status":400}
The relevant failure reason here is given with a "NO" (all infos marked with "YES" basically passed):
[NO(cannot allocate replica shard to a node with version [6.5.4] since this is older than the primary version [6.8.3])]
In such a case make sure Elasticsearch on all nodes is the same version, in this case both should run on either 6.5.x or 6.8.x.
No comments yet.

AWS Android Ansible Apache Apple Atlassian BSD Backup Bash Bluecoat CMS Chef Cloud Coding Consul Containers CouchDB DB DNS Databases Docker ELK Elasticsearch Filebeat FreeBSD Galera Git GlusterFS Grafana Graphics HAProxy HTML Hacks Hardware Icinga Influx Internet Java KVM Kibana Kodi Kubernetes LVM LXC Linux Logstash Mac Macintosh Mail MariaDB Minio MongoDB Monitoring Multimedia MySQL NFS Nagios Network Nginx OSSEC OTRS Observability Office OpenSearch PHP Perl Personal PostgreSQL PowerDNS Proxmox Proxy Python Rancher Rant Redis Roundcube SSL Samba Seafile Security Shell SmartOS Solaris Surveillance Systemd TLS Tomcat Ubuntu Unix VMware Varnish Virtualization Windows Wireless Wordpress Wyse ZFS Zoneminder