Last update: May 09, 2026
check_smart is a monitoring plugin to monitor the values of SMART (Self-Monitoring, Analysis and Reporting Technology) attributes of hard and solid state drives, using smartmontool's smartctl in the background.
(S)ATA, SCSI/SAS and NVMe drives are supported. The plugin is a fork of check_smart released in 2009 by Kurt Yoder. Since then the plugin has undergone a lot of changes. It allows to monitor drives behind hardware controllers and added a lot of parameters to fine tune the checks and set thresholds (on a per attribute setting).

Monitoring of physical hard drives (HDDs), solid state drives (SSDs) or NVMe drives is crucial in production environments. Whether the drives are running in a server or on a workstation, you want to know if a drive is starting to fail so you can pro-actively plan actions - before it's too late. See the following articles for real life examples:
Depending on the type of the drive, the SMART output is different. The plugin is able to handle ATA, SCSI and NVMe drives and adjust itself to the SMART output of these different interface types.
As of this writing (March 2020), the most used drives are currently ATA-based hard or solid state drives. The (S)ATA interface exists on all motherboards, the SATA standard is currently in version 3 allowing theoretical transfer speeds of up to 6Gbit/s. Both hard drives and solid state drives (with a SATA connector) are using the ATA SMART output.
The ATA S.M.A.R.T. table features a list of SMART attributes. These attributes can either be counters (example: Power_On_Hours) or show a specific value (example: Temperature). The attribute names are not always the same, depending on the vendors of the physical drive. A good overview of existing attributes can be found on Wikipedias SMART page.
The check_smart monitoring plugin runs a couple of checks on ATA drives. First the current health status of the drive is retrieved. If health of the drive seems to be OK, the plugin will retrieve all the SMART attributes and their current values and compare them to given thresholds (using the -w parameter, optional). The plugin adds performance data on single drive checks which is handy to long-term monitoring of drives.
Compared to ATA drives, SCSI drives do not have SMART attributes. The available data for analysis and pre-failure guessing is very limited. Basically the relevant information can only be found in the grown defect list counter. check_smart is actively monitoring this counter (thresholds are possible with -b parameter), besides doing the normal health and temperature checks.
The usage of SCSI drives is declining due to the rise of ATA-based SSD and NVMe drives. However note that SAS drives are basically SCSI drives and are still widely used in enterprise servers.
NVMe drives use, like ATA drives, a list of SMART attributes to help identify (pre-fail) problems of a drive. However the attributes are not compatible with the ATA attributes. check_smart mainly focuses on the Critical_Warning attribute which represents the drive status. The plugin also actively monitors the Media_and_Data_Integrity_Errors counter which could help to identify a failing NVMe drive.
The plugin adds performance data on single drive checks which is handy to long-term monitoring of drives.
Monitoring of NVMe drives is possible since check_smart 6.7.0.
If you are looking for commercial support for this monitoring plugin, need customized modifications or in general customized monitoring plugins, contact us at Infiniroot.com.

195009 downloads so far...
Download plugin and save it in your Nagios/Monitoring plugin folder (usually /usr/lib/nagios/plugins, depends on your distribution). Afterwards adjust the permissions (usually chmod 755).
Community contributions welcome on GitHub repo.
The check_smart plugin is available on RPM-based Linux distributions as package monitoring-plugins-smart, maintained in the server:monitoring repository. Check the link for available Linux distributions.
Feb 3, 2009: Kurt Yoder - initial version of script (rev 1.0)
Jul 8, 2013: Claudio Kuenzler - support hardware raids like megaraid (rev 2.0)
Jul 9, 2013: Claudio Kuenzler - update help output (rev 2.1)
Oct 11, 2013: Claudio Kuenzler - making the plugin work on FreeBSD (rev 3.0)
Oct 11, 2013: Claudio Kuenzler - allowing -i sat (SATA on FreeBSD) (rev 3.1)
Nov 4, 2013: Claudio Kuenzler - works now with CCISS on FreeBSD (rev 3.2)
Nov 4, 2013: Claudio Kuenzler - elements in grown defect list causes warning (rev 3.3)
Nov 6, 2013: Claudio Kuenzler - add threshold option "bad" (-b) (rev 4.0)
Nov 7, 2013: Claudio Kuenzler - modified help (rev 4.0)
Nov 7, 2013: Claudio Kuenzler - bugfix in threshold logic (rev 4.1)
Mar 19, 2014: Claudio Kuenzler - bugfix in defect list perfdata (rev 4.2)
Apr 22, 2014: Jerome Lauret - implemented -g to do a global lookup (rev 5.0)
Apr 25, 2014: Claudio Kuenzler - cleanup, merge Jeromes code, perfdata output fix (rev 5.1)
May 5, 2014: Caspar Smit - Fixed output bug in global check / issue #3 (rev 5.2)
Feb 4, 2015: Caspar Smit and cguadall - Allow detection of more than 26 devices / issue #5 (rev 5.3)
Feb 5, 2015: Bastian de Groot - Different ATA vs. SCSI lookup (rev 5.4)
Feb 11, 2015: Josh Behrends - Allow script to run outside of nagios plugins dir / wiki url update (rev 5.5)
Feb 11, 2015: Claudio Kuenzler - Allow script to run outside of nagios plugins dir for FreeBSD too (rev 5.5)
Mar 12, 2015: Claudio Kuenzler - Change syntax of -g parameter (regex is now awaited from input) (rev 5.6)
Feb 6, 2017: Benedikt Heine - Fix Use of uninitialized value $device (rev 5.7)
Oct 10, 2017: Bobby Jones - Allow multiple devices for interface type megaraid, e.g. "megaraid,[1-5]" (rev 5.8)
Apr 28, 2018: Pavel Pulec (Inuits) - allow type "auto" (rev 5.9)
May 5, 2018: Claudio Kuenzler - Check selftest log for errors using new parameter -s (rev 5.10)
Dec 27, 2018: Claudio Kuenzler - Add exclude list (-e) to ignore certain attributes (5.11)
Jan 8, 2019: Claudio Kuenzler - Fix 'Use of uninitialized value' warnings (5.11.1)
Jun 4, 2019: Claudio Kuenzler - Add raw check list (-r) and warning thresholds (-w) (6.0)
Jun 11, 2019: Claudio Kuenzler - Allow using pseudo bus device /dev/bus/N (6.1)
Aug 19, 2019: Claudio Kuenzler - Add device model and serial number in output (6.2)
Oct 1, 2019: Michael Krahe - Allow exclusion from perfdata as well (-E) and by attribute number (6.3)
Oct 29, 2019: Jesse Becker - Remove dependency on utils.pm, add quiet parameter (6.4)
Nov 22, 2019: Claudio Kuenzler - Add Reported_Uncorrect and Reallocated_Event_Count to default raw list (6.5)
Nov 29, 2019: Claudio Kuenzler - Add 3ware and cciss devices for global (-g) check, adjust output (6.6)
Dec 4, 2019: Ander Punnar - Fix 'deprecation warning on regex with curly brackets' (6.6.1)
Mar 25, 2020: Claudio Kuenzler - Add support for NVMe devices (6.7.0)
Jun 2, 2020: Claudio Kuenzler - Bugfix to make --warn work (6.7.1)
Oct 14, 2020: Claudio Kuenzler - Allow skip self-assessment check (--skip-self-assessment) (6.8.0)
Oct 14, 2020: Claudio Kuenzler - Add Command_Timeout to default raw list (6.8.0)
Mar 3, 2021: Evan Felix - Allow use of colons in pathnames so /dev/disk/by-path/ device names work (6.9.0)
Mar 4, 2021: Claudio Kuenzler - Add SSD attribute Percent_Lifetime_Remain check (-l|--ssd-lifetime) (6.9.0)
Apr 8, 2021: Claudio Kuenzler - Fix regex for pseudo-devices (6.9.1)
Jul 6, 2021: Bernhard Bittner - Add aacraid devices (6.10.0)
Oct 4, 2021: Claudio Kuenzler + Peter Newman - Handle dots in NVMe attributes, prioritize (order) alerts (6.11.0)
Dec 10, 2021: Claudio Kuenzler - Security fix in path for pseudo-devices, add Erase_Fail_Count_Total, fix NVMe perfdata (6.12.0)
Dec 10, 2021: Claudio Kuenzler - Bugfix in interface handling (6.12.1)
Dec 16, 2021: Lorenz Kaestle - Bugfix when interface parameter was missing in combination with -g (6.12.2)
Apr 27, 2022: Claudio Kuenzler - Allow skip temperature check (--skip-temp-check) (6.13.0)
Apr 27, 2022: Peter Newman - Better handling of missing or non-executable smartctl command (6.13.0)
Apr 29, 2023: Nick Bertrand - Show drive(s) causing UNKNOWN status using -g/--global check (6.14.0)
Apr 29, 2023: Claudio Kuenzler - Add possibility to hide serial number (--hide-sn) (6.14.0)
Apr 29, 2023: Claudio Kuenzler - Add default check on Load Cycle Count (ignore using --skip-load-cycles) (6.14.0)
Sep 20, 2023: Yannick Martin - Fix default Percent_Lifetime_Remain threshold handling when -w is given (6.14.1)
Sep 20, 2023: Claudio Kuenzler - Fix debug output for raw check list, fix --hide-serial in debug output (6.14.1)
Mar 15, 2024: Yannick Martin - Fix nvme check when auto interface is given and device is nvme (6.14.2)
Sep 10, 2024: Claudio Kuenzler - Fix performance data format, missing perfdata in SCSI drives (6.14.3)
Jan 31, 2025: Tomas Barton - Ignore old age attributes due to its unrealiability. Check ATA error logs (6.15.0)
Jun 12, 2025: Alexander Kanevskiy - Add usbjmicron devices (6.16.0)
Dec 15, 2025: Florian Sager - Fix evaluating ATA Error Count: 0 as a warning (6.17.0)
Dec 15, 2025: Philippe Beaumont - Add areca devices (6.17.0)
Apr 20, 2026: Claudio Kuenzler - Fix sys path for sudo command. Detect NVME input/output error (6.18.0)
Apr 24, 2026: Claudio Kuenzler - Fix command injection vulnerability in interface parameter (6.18.1)
May 9, 2026: Claudio Kuenzler - Fix regression with symlink paths (6.18.2)
This plugin needs to run as root, otherwise you're not able to lauch smartctl correctly. You have two options:
Here are some examples you can add to your sudoers with the command "visudo":
nagios ALL = NOPASSWD: /usr/local/libexec/nagios/check_smart.pl # for option 1 on FreeBSD
nagios ALL = NOPASSWD: /usr/local/sbin/smartctl # for option 2 on FreeBSD
nagios ALL = NOPASSWD: /usr/lib/nagios/plugins/check_smart.pl # for option 1 on Linux
nagios ALL = NOPASSWD: /usr/sbin/smartctl # for option 2 on Linux
| Short | Long | Description |
| -d* | --device* | A physical block device to be SMART monitored, eg /dev/sda. Since 6.9.0 disk pci path is also working (/dev/disk/by-path/pci-0000:03:00.1-ata-1). Pseudo-device /dev/bus/N is allowed. |
| -g* | --global* | A glob expression of physical devices to be monitored, eg -g "/dev/sd[a-z]" for devices /dev/sda until /dev/sdz or -g "/dev/sd{a,b,d}" for devices /dev/sda, /dev/sdb and /dev/sdd. If you have many drives exceeding the letter Z, you can use -g "/dev/sd*[a-z]" for all /dev/sda until /dev/sdzzzz. It is also possible to use -g in conjunction with drives behind megaraid, cciss or 3ware controllers. Example: -g /dev/sda -i 'megaraid,[0-3]'. The global check allows to quickly identify obvious errors on multiple drives, however it will not show details of each drive. This parameter will omit performance data. For a detailed check including performance data for historical graphing, a single drive check (using -d) is advised. |
| -i* | --interface* | Drive's interface type, must be one of: auto, ata, scsi, nvme, 3ware,N, areca,N, hpt,L/M/N, cciss,N, megaraid,N, aacraid,N,N,N, usbjmicron,N See Supported RAID-Controllers on the Smartmontools wiki for interface types If used in combination with -g/--global, megaraid, 3ware and cciss interface supports glob expression, eg -i "megaraid,[8-9]" |
| -r | --raw | List (comma separated, without spaces!) of SMART attributes to check for their raw values. ATA default: 'Current_Pending_Sector, Reallocated_Sector_Ct, Program_Fail_Cnt_Total, Uncorrectable_Error_Cnt, Offline_Uncorrectable, Runtime_Bad_Block, Reported_Uncorrect, Reallocated_Event_Count' NVMe default: 'Media_and_Data_Integrity_Errors' |
| -b | --bad | Threshold value (integer) when to warn for N bad entries (ATA: Current Pending Sector, SCSI: Grown defect list) Note: Deprecated for ATA since check_smart version 6.0, use -w instead. Continue to use -b for SCSI drives. |
| -w | --warn | Comma separated list of thresholds for ATA drives (e.g. -w 'Reallocated_Sector_Ct=10,Current_Pending_Sector=62'). |
| -e | --exclude | List of (comma separated) SMART attributes which should be excluded (=ignored) from checks. Note that these attributes still appear in performance data. Also supports "When_failed" values, e.g. "In_the_past" or "FAILING_NOW". |
| -E | --exclude-all | List of (comma separated) SMART attributes which should be excluded (=ignored) completely, for both checks and performance data. Also supports "When_failed" values, e.g. "In_the_past" or "FAILING_NOW". |
| -s | --selftest | Additionally check SMART's selftest log for errors. |
| -l | --ssd-lifetime | Additionally check attribute 'Percent_Lifetime_Remain' which is available on some SSD drives. Note that this counter is "reversed" meaning it starts from 0. This could be confusing to some, but makes sense for setting a threshold at a value close to 100. By enabling this option, 'Percent_Lifetime_Remain=90' is added to the warning list. See details for more information. |
| -O | --oldage | Ignore certain "oldage" attributes related to the drive's usage. Only use this if you know what you are doing! Currently this affects ATA attribute 202 (Percent_Lifetime_Used) and NVMe attribute Critical_Warning in state 0x04. |
| -q | --quiet | When faults are detected, only show failing drive(s) (only affects output when used with -g parameter). |
| -h | --help | Show help/usage |
| -v | --version | Show plugin version |
| N/A | --skip-self-assessment | Skip the SMART self assessment health check (not recommended). |
| N/A | --skip-temp-check | Skip temperature comparison current vs. drive max temperature (not recommended). |
| N/A | --skip-load-cycles | Skip check of SMART attribute 193 (Load_Cycle_Count), deemed unsafe after reaching 600K load/unload cycles. |
| N/A | --skip-error-log | Skip check of SMART Error Log (by default enabled since v6.15.0). |
| N/A | --hide-sn | Do not show serial number of drive(s) in output. |
| N/A | --debug | Show debugging information |
* mandatory parameter
Either -d or -g parameter is required. -i is always required.
-e and -E exclude lists can co-exist.
Usage:
./check_smart.pl (-d string|-g regex) -i string [-r list] [-w list] [-b int] [-e list] [-s] [--debug]
Example: Single SATA Drive:
./check_smart.pl -d /dev/sda -i ata
WARNING: Reallocated_Sector_Ct is non-zero (3), Program_Fail_Cnt_Total is non-zero (3), Runtime_Bad_Block is non-zero (3), Uncorrectable_Error_Cnt is non-zero (1)|Reallocated_Sector_Ct=3 Power_On_Hours=31415 Power_Cycle_Count=889 Program_Fail_Count_Chip=2 Erase_Fail_Count_Chip=0 Wear_Leveling_Count=873 Used_Rsvd_Blk_Cnt_Chip=386 Used_Rsvd_Blk_Cnt_Tot=752 Unused_Rsvd_Blk_Cnt_Tot=3280 Program_Fail_Cnt_Total=3 Erase_Fail_Count_Total=0 Runtime_Bad_Block=3 Uncorrectable_Error_Cnt=1 ECC_Error_Rate=1 Offline_Uncorrectable=0 CRC_Error_Count=262 Available_Reservd_Space=1630 Total_LBAs_Written=3363787529 Total_LBAs_Read=3278685684
Example: Single SATA Drive with warning thresholds:
./check_smart.pl -d /dev/sda -i ata -w 'Reallocated_Sector_Ct=4,Runtime_Bad_Block=4,Uncorrectable_Error_Cnt=2'
WARNING: Reallocated_Sector_Ct is non-zero (3) (but less than threshold 4), Program_Fail_Cnt_Total is non-zero (3), Runtime_Bad_Block is non-zero (3) (but less than threshold 4), Uncorrectable_Error_Cnt is non-zero (1) (but less than threshold 2)|Reallocated_Sector_Ct=3 Power_On_Hours=31415 Power_Cycle_Count=889 Program_Fail_Count_Chip=2 Erase_Fail_Count_Chip=0 Wear_Leveling_Count=873 Used_Rsvd_Blk_Cnt_Chip=386 Used_Rsvd_Blk_Cnt_Tot=752 Unused_Rsvd_Blk_Cnt_Tot=3280 Program_Fail_Cnt_Total=3 Erase_Fail_Count_Total=0 Runtime_Bad_Block=3 Uncorrectable_Error_Cnt=1 ECC_Error_Rate=1 Offline_Uncorrectable=0 CRC_Error_Count=262 Available_Reservd_Space=1630 Total_LBAs_Written=3363863033 Total_LBAs_Read=3278685684
Example: Single SATA Drive but exclude certain attribute checks (yet keep the attribute data in performance data):
./check_smart.pl -d /dev/sda -i ata -e 'Reallocated_Sector_Ct,Program_Fail_Cnt_Total'
WARNING: Runtime_Bad_Block is non-zero (3), Uncorrectable_Error_Cnt is non-zero (1)|Reallocated_Sector_Ct=3 Power_On_Hours=31416 Power_Cycle_Count=889 Program_Fail_Count_Chip=2 Erase_Fail_Count_Chip=0 Wear_Leveling_Count=873 Used_Rsvd_Blk_Cnt_Chip=386 Used_Rsvd_Blk_Cnt_Tot=752 Unused_Rsvd_Blk_Cnt_Tot=3280 Program_Fail_Cnt_Total=3 Erase_Fail_Count_Total=0 Runtime_Bad_Block=3 Uncorrectable_Error_Cnt=1 ECC_Error_Rate=1 Offline_Uncorrectable=0 CRC_Error_Count=262 Available_Reservd_Space=1630 Total_LBAs_Written=3363924329 Total_LBAs_Read=3278685684
Example: Single SATA Drive but completely exclude certain attribute from check and performance data:
./check_smart.pl -d /dev/sda -i ata -E 'Reallocated_Sector_Ct,Program_Fail_Cnt_Total'
WARNING: Runtime_Bad_Block is non-zero (3), Uncorrectable_Error_Cnt is non-zero (1)|Power_On_Hours=31416 Power_Cycle_Count=889 Program_Fail_Count_Chip=2 Erase_Fail_Count_Chip=0 Wear_Leveling_Count=873 Used_Rsvd_Blk_Cnt_Chip=386 Used_Rsvd_Blk_Cnt_Tot=752 Unused_Rsvd_Blk_Cnt_Tot=3280 Erase_Fail_Count_Total=0 Runtime_Bad_Block=3 Uncorrectable_Error_Cnt=1 ECC_Error_Rate=1 Offline_Uncorrectable=0 CRC_Error_Count=262 Available_Reservd_Space=1630 Total_LBAs_Written=3363924329 Total_LBAs_Read=3278685684
Example: Single SATA Drive with manual override which attributes should be checked for their raw values:
./check_smart.pl -d /dev/sda -i ata -r 'Uncorrectable_Error_Cnt'
WARNING: Uncorrectable_Error_Cnt is non-zero (1)|Reallocated_Sector_Ct=3 Power_On_Hours=31416 Power_Cycle_Count=889 Program_Fail_Count_Chip=2 Erase_Fail_Count_Chip=0 Wear_Leveling_Count=873 Used_Rsvd_Blk_Cnt_Chip=386 Used_Rsvd_Blk_Cnt_Tot=752 Unused_Rsvd_Blk_Cnt_Tot=3280 Program_Fail_Cnt_Total=3 Erase_Fail_Count_Total=0 Runtime_Bad_Block=3 Uncorrectable_Error_Cnt=1 ECC_Error_Rate=1 Offline_Uncorrectable=0 CRC_Error_Count=262 Available_Reservd_Space=1630 Total_LBAs_Written=3363995193 Total_LBAs_Read=3278685684
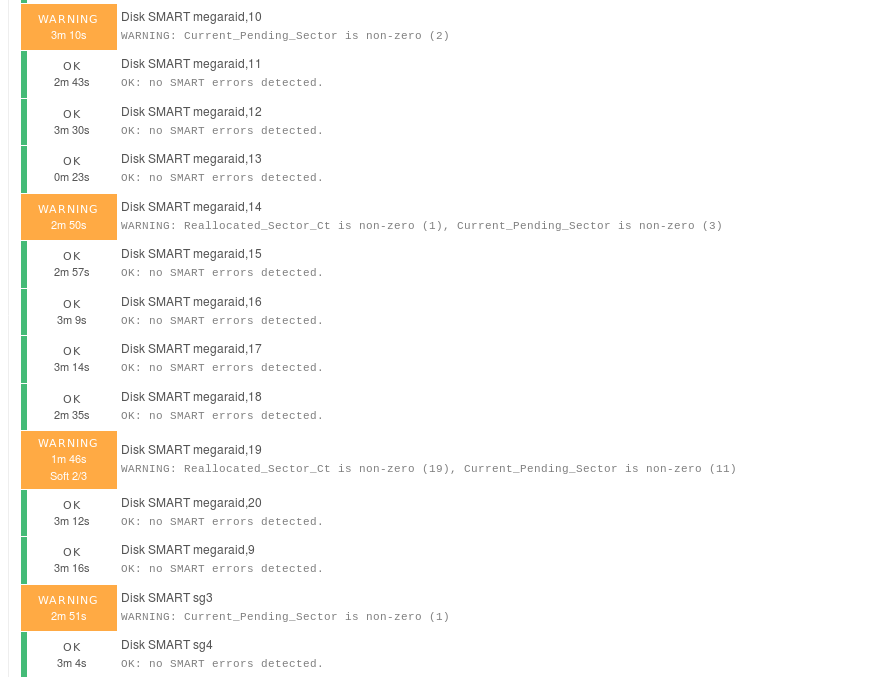
Example: Drive attached to MegaRAID controller:
./check_smart.pl -d /dev/sda -i megaraid,8
Example: Intel RAID on FreeBSD 9.2 ("kldload mfip.ko" required):
/usr/local/libexec/nagios/check_smart.pl -d /dev/pass0 -i scsi
Example: SATA drives behind Intel RAID on FreeBSD 9.2 ("kldload mfip.ko" required):
/usr/local/libexec/nagios/check_smart.pl -d /dev/pass12 -i sat
Example: SCSI drives behind HP RAID (CCISS) on FreeBSD 6.0:
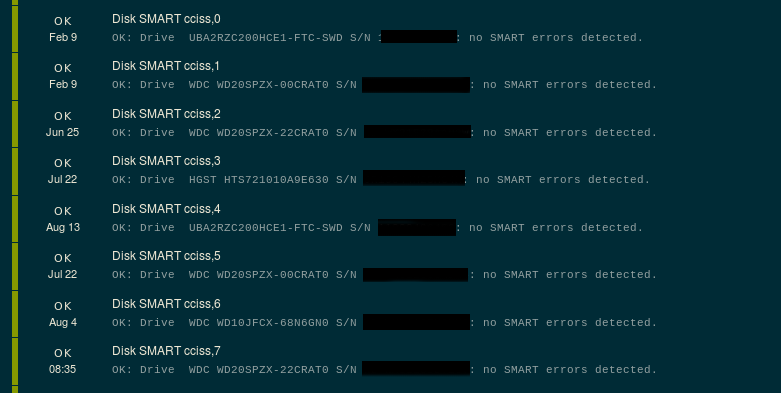
/usr/local/libexec/nagios/check_smart.pl -d /dev/ciss0 -i cciss,0
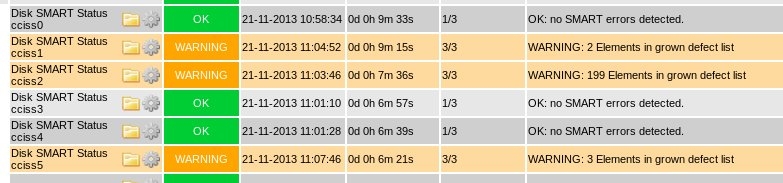
OK: no SMART errors detected|defect_list=0 sent_blocks=3093462752 temperature=24;;68
/usr/local/libexec/nagios/check_smart.pl -d /dev/ciss0 -i cciss,3
WARNING: 48 Elements in grown defect list | defect_list=48 sent_blocks=1137657348 temperature=22;;68
Example: Using threshold option (-b) to ignore 1 bad element, warning only when 2 bad elements are found:
/usr/local/libexec/nagios/check_smart.pl -d /dev/ciss0 -i cciss,1 -b 2
OK: 1 Elements in grown defect list (but less than threshold 2)|defect_list=1;2;2;; sent_blocks=2769458900762624 temperature=27;;65
Example: Check all SATA disks (sda - sdz) at the same time on Linux:
/usr/lib/nagios/plugins/check_smart.pl -g "/dev/sd[a-z]" -i ata
OK: [/dev/sda] - Device is clean --- [/dev/sdb] - Device is clean|
Example: Check all SCSI disks behind Intel RAID on FreeBSD 9.2 ("kldload mfip.ko" required):
/usr/local/libexec/nagios/check_smart.pl -g "/dev/pass[1-9]" -i scsi
OK: [/dev/pass0] - Device is clean --- [/dev/pass1] - Device is clean --- [/dev/pass2] - Device is clean --- [/dev/pass3] - Device is clean --- [/dev/pass4] - Device is clean --- [/dev/pass5] - Device is clean --- [/dev/pass6] - Device is clean --- [/dev/pass7] - Device is clean --- [/dev/pass8] - Device is clean --- [/dev/pass9] - Device is clean |
Example: Single SCSI drive on FreeBSD 10.1:
/usr/local/libexec/nagios/check_smart.pl -d /dev/da0 -i scsi
OK: no SMART errors detected. |sent_blocks=14067306 temperature=34;;60
Example: Check multiple drives behind a HP Proliant raid controller (cciss interface):
/usr/lib/nagios/plugins/check_smart.pl -g /dev/sda -i "cciss,[0-3]"
OK: [cciss,1] - Device is clean --- [cciss,2] - Device is clean --- [cciss,3] - Device is clean|
Example: Check a single drive behind USBJMICRON bridge:
/usr/lib/nagios/plugins/check_smart.pl -d /dev/sda -i usbjmicron,0
WARNING: Drive ST9500620NS S/N 9Xxxxxxxx: Reported_Uncorrect is non-zero (1), ata_errors is non-zero (2), |Raw_Read_Error_Rate=89026159;;;; Spin_Up_Time=0;;;; Start_Stop_Count=65;;;; Reallocated_Sector_Ct=0;;;; Seek_Error_Rate=384038545;;;; Power_On_Hours=52407;;;; Spin_Retry_Count=0;;;; Power_Cycle_Count=64;;;; End-to-End_Error=0;;;; Reported_Uncorrect=1;;;; Command_Timeout=0;;;; High_Fly_Writes=0;;;; Airflow_Temperature_Cel=22;;;; G-Sense_Error_Rate=0;;;; Power-Off_Retract_Count=63;;;; Load_Cycle_Count=65;;;; Temperature_Celsius=22;;;; Hardware_ECC_Recovered=89026159;;;; Current_Pending_Sector=0;;;; Offline_Uncorrectable=0;;;; UDMA_CRC_Error_Count=0;;;; Head_Flying_Hours=47281;;;; Total_LBAs_Written=2698006791;;;; Total_LBAs_Read=3579624246;;;; ata_errors=2;;;;
Example: Check a single NVMe drive:
/usr/lib/nagios/plugins/check_smart.pl -d /dev/nvme0 -i nvme
OK: Drive Samsung SSD 970 PRO 512GB S/N XXXXXXXXXXXXXXX: no SMART errors detected. |Temperature=34 Available_Spare=100 Available_Spare_Threshold=10 Percentage_Used=0 Data_Units_Read=2854 Data_Units_Written=107590 Host_Read_Commands=67150 Host_Write_Commands=1406316 Controller_Busy_Time=20 Power_Cycles=16 Power_On_Hours=105 Unsafe_Shutdowns=6 Media_and_Data_Integrity_Errors=0 Error_Information_Log_Entries=0 Warning__Comp._Temperature_Time=0 Critical_Comp._Temperature_Time=0 Temperature_Sensor_1=34 Temperature_Sensor_2=33
Example: Check multiple NVMe drives:
/usr/lib/nagios/plugins/check_smart.pl -g "/dev/nvme[0-9]" -i nvme
OK: [/dev/nvme0] - Device is clean --- [/dev/nvme1] - Device is clean|
Also see CheckCommand object in GitHub repository
/*
* Icinga2 CheckCommand definition for check_smart (check_smart.pl) monitoring plugin
* See https://www.claudiokuenzler.com/monitoring-plugins/check_smart.php
*/
object CheckCommand "check_smart" {
import "plugin-check-command"
command = [ "/usr/bin/sudo", PluginContribDir + "/check_smart.pl", ]
arguments = {
"-d" = {
value = "$smart_device$"
set_if = {{ macro("$smart_device_is_glob$") == false }}
description = "A physical block device to be SMART monitored, eg /dev/sda."
}
"-g" = {
value = "$smart_device$"
set_if = {{ macro("$smart_device_is_glob$") == true }}
description = "A glob expression of physical devices to be monitored, eg -g '/dev/sd[a-z]'."
}
"-i" = {
value = "$smart_interface$"
description = "Drive's interface type, must be one of: auto, ata, scsi, nvme, 3ware,N, areca,N, hpt,L/M/N, cciss,N, megaraid,N."
required = true
}
"-r" = {
value = "$smart_raw_list$"
description = "List (comma separated, without spaces!) of SMART attributes to check for their raw values."
}
"-e" = {
value = "$smart_exclude_list$"
description = "List of (comma separated) SMART attributes which should be excluded (=ignored) from checks, but still appear in perfdata."
}
"-E" = {
value = "$smart_exclude_all_list$"
description = "List of (comma separated) SMART attributes which should be excluded (=ignored) completely from checks and perfdata."
}
"-b" = {
value = "$smart_bad$"
description = "Threshold value (integer) when to warn for N bad entries (ATA: Current Pending Sector, SCSI: Grown defect list). Note: Deprecated for ATA drives, use `smart_warn` instead. Continue to use this for SCSI drives."
}
"-w" = {
value = "$smart_warn$"
description = "Comma separated list of thresholds for ATA drives (e.g. `'Reallocated_Sector_Ct=10,Current_Pending_Sector=62'`)."
}
"-s" = {
set_if = "$smart_selftest$"
description = "If set to true, additionally check SMART's selftest log for errors."
}
"-l" = {
set_if = "$smart_ssd_lifetime$"
description = "If set to true, additionally check SSD attribute Percent_Lifetime_Remain."
}
"-O" = {
set_if = "$smart_oldage$"
description = "If set to true, ignore certain oldage attributes related to the drive's usage (not recommended)."
}
"-q" = {
set_if = "$smart_quiet$"
description = "If set to true, only show failing drive(s) when faults are detected (only affects output when used with `vars.smart_device_is_glob`)."
}
"--hide-sn" = {
set_if = "$smart_hide_sn$"
description = "If set to true, output does not reveal serial number of drive(s)."
}
"--skip-self-assessment" = {
set_if = "$smart_skip_self_assessment$"
description = "If set to true, skip the SMART self assessment health check (not recommended)."
}
"--skip-temp-check" = {
set_if = "$smart_skip_temp_check$"
description = "If set to true, skip temperature comparison current vs. drive max temperature (not recommended)."
}
"--skip-load-cycles" = {
set_if = "$smart_skip_load_cycles$"
description = "If set to true, skip check of SMART attribute 193 (Load_Cycle_Count), deemed unsafe after reaching 600K load/unload cycles."
}
"--skip-error-log" = {
set_if = "$smart_skip_error_log$"
description = "If set to true, skip check of SMART Error Log (not recommended)."
}
}
vars.smart_interface = "auto"
vars.smart_device_is_glob = false
vars.smart_selftest = false
vars.smart_ssd_lifetime = false
vars.smart_quiet = false
}
Example command definition for single drive in your nrpe.cfg:
command[check_smart]=sudo /usr/lib/nagios/plugins/check_smart.pl -d $ARG1$ -i $ARG2$ -w $ARG3$
Example command definition for multiple drives using -g parameter in your nrpe.cfg:
command[check_smart_multidrive]=sudo /usr/lib/nagios/plugins/check_smart.pl -g $ARG1$ -i $ARG2$ -w $ARG3$
Basic check of a single drive (or drive in software raid):
# Check SMART of a typical single disk (or used in software
raid)
define service{
use generic-service
host_name mylinux1
service_description Disk SMART Status SDA
check_command check_nrpe!check_smart!-a "/dev/sda" "sat" "Current_Pending_Sector=14,Reallocated_Sector_Count=3"
}
Check SMART of multiple disks at same time:
# Check SMART of multiple disks with regex (looking for /dev/sda until /dev/sdf)
define service{
use generic-service
host_name mylinux1
service_description Disk SMART Status
check_command check_nrpe!check_smart_all!-a "/dev/sd[a-f]" "sat" "Current_Pending_Sector=14,Reallocated_Sector_Count=3"
}
Check SMART of a drive behind a cciss (HP SmartArray) controller:
# Check SMART of a drive behind a cciss (HP SmartArray)
raid controller
define service{
use generic-service
host_name myhpproliant1
service_description Disk SMART Status cciss2
check_command check_nrpe!check_smart!-a "/dev/cciss/c0d0" "cciss,2" "Current_Pending_Sector=14,Reallocated_Sector_Count=3"
}
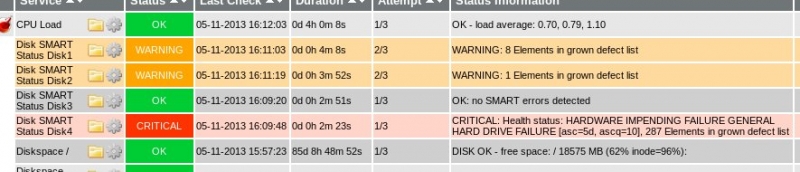
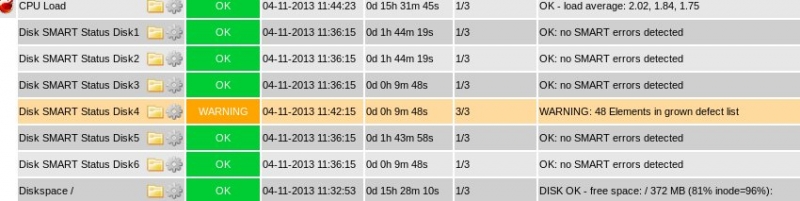
Here the argument 3 ($ARG3$) is "Current_Pending_Sector=14,Reallocated_Sector_Count=3". This means that this drive already has 13 pending sectors and 2 reallocated sectors. The warning thesholds are set to 14 for the Current_Pending_Sector attribute and to 3 for the Reallocated_Sector_Count attribute. As soon as the drive reaches 14 (or more) pending sectors or 3 (or more) reallocated sectors, the plugin will return a warning. This helps to see if a disk is really failing and the number of defect sectors are growing.
Check a single SATA drive with specific warning threshold
# SMART Check of drive sda
object Service "Disk SMART sda" {
import "generic-service"
host_name "linuxserver1"
check_command = "nrpe"
vars.nrpe_command = "check_smart"
vars.nrpe_arguments = ["/dev/sda", "ata", "Current_Pending_Sector=14,Reallocated_Sector_Count=3"]
}
Check a single SATA drive with specific warning threshold
# SMART Check of drive sda
object Service "Disk SMART sda" {
import "generic-service"
host_name "linuxserver1"
check_command = "check_smart"
vars.smart_device = "/dev/sda"
vars.smart_interface = "ata"
vars.smart_warn = "Current_Pending_Sector=14,Reallocated_Sector_Count=3"
}
The following example shows a service apply rule in Icinga 2, based on the Host object's variables listing the disks inside the host.vars.
First the Host definition, containing the custom host variables:
object Host "linuxserver1" {
import "generic-host"
address = "xxx.xxx.xxx.xxx"
# Physical drives
vars.drives["cciss,0"] = { "smart_device" = "/dev/sda", "smart_interface" = "cciss,0" }
vars.drives["cciss,1"] = { "smart_device" = "/dev/sda", "smart_interface" = "cciss,1", "smart_warn" = "Command_Timeout=48" }
}
And the service apply rule:
## Service apply rule for check_smart checks
apply Service "Disk SMART " for (drivename => config in host.vars.drives) {
import "generic-service"
vars += config
display_name = "Disk SMART " + drivename
check_command = "check_smart"
assign where host.address && host.vars.drives
}