
Wow! Who'd thought that the new version of check_smart.pl (see last article "check_smart.pl adapted to support cciss and handle grown defect list" for details) would become a life saver for old servers!
Usually I monitor all server hardware through ILO with the Nagios plugin check_ilo2_health.pl. Unfortunately the hard drive monitoring was only added in newer ILO3 firmware. Therefore all ILO2 servers still running (e.g. ProLiant G5 servers) are kind of "in the grey" when it comes to hardware monitoring.
When check_smart.pl is correctly used, this can be a life saver. The following screenshot speaks for itself, doesn't it?
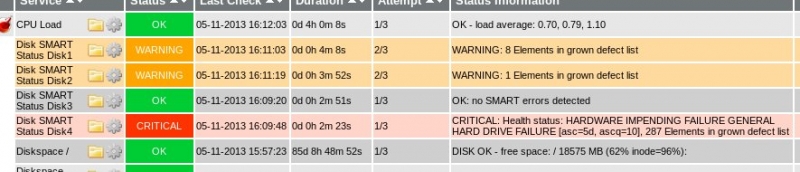
Phew... That was close!
Update November 6th 2013
As soon as I removed disk #4 from the chassis, the server/raid controller finally detected a disk as failed. Disk #1 started to blink red (before that, the server's LED's were all green and ILO showed server health as OK, too). In dmesg the following entries appeared:
ciss0: *** Drive failure imminent, Port=1I Box=1 Bay=1
ciss0: *** Hot-plug drive removed, Port=1I Box=1 Bay=4
ciss0: *** Physical drive failure, Port=1I Box=1 Bay=4
ciss0: *** State change, logical drive 1
ciss0: logical drive 1 (da1) changed status OK->interim recovery, spare status 0x0
ciss0: *** Hot-plug drive inserted, Port=1I Box=1 Bay=4
ciss0: *** State change, logical drive 1
ciss0: logical drive 1 (da1) changed status interim recovery->ready for recovery, spare status 0x0
ciss0: *** State change, logical drive 1
ciss0: logical drive 1 (da1) changed status ready for recovery->recovering, spare status 0x0
Then it was up to disk #1 to be replaced:
ciss0: *** Hot-plug drive removed, Port=1I Box=1 Bay=1
ciss0: *** Physical drive failure, Port=1I Box=1 Bay=1
ciss0: *** State change, logical drive 0
ciss0: logical drive 0 (da0) changed status OK->interim recovery, spare status 0x0
ciss0: *** Hot-plug drive inserted, Port=1I Box=1 Bay=1
ciss0: *** State change, logical drive 0
ciss0: logical drive 0 (da0) changed status interim recovery->ready for recovery, spare status 0x0
I also saw that the raid recovery didn't start on logical drive 0 (physical drives 1+2) yet because the recovery of logical drive 1 (physical drives 3+4) was still running. So it seems that the raid controller can only do a raid recovery on one logical drive at a time. As soon as the first recovery was finished, the second started immediately:
ciss0: *** State change, logical drive 1
ciss0: logical drive 1 (da1) changed status recovering->OK, spare status 0x0
ciss0: *** State change, logical drive 0
ciss0: logical drive 0 (da0) changed status ready for recovery->recovering, spare status 0x0
ciss0: *** State change, logical drive 0
ciss0: logical drive 0 (da0) changed status recovering->OK, spare status 0x0
No comments yet.

AI AWS Android Ansible Apache Apple Atlassian BSD Backup Bash Bluecoat CMS Chef Cloud Coding Consul Containers CouchDB DB DNS Databases Docker ELK Elasticsearch Filebeat FreeBSD Galera Git GlusterFS Grafana Graphics HAProxy HTML Hacks Hardware Icinga Influx Internet Java KVM Kibana Kodi Kubernetes LVM LXC Linux Logstash Mac Macintosh Mail MariaDB Minio MongoDB Monitoring Multimedia MySQL NFS Nagios Network Nginx OSSEC OTRS Observability Office OpenSearch PHP Perl Personal PostgreSQL PowerDNS Proxmox Proxy Python Rancher Rant Redis Roundcube SSL Samba Seafile Security Shell SmartOS Solaris Surveillance Systemd TLS Tomcat Ubuntu Unix VMware Varnish Virtualization Windows Wireless Wordpress Wyse ZFS Znuny Zoneminder