
Kubernetes requires a ton of privileges, sometimes wanting to set its own Kernel parameters. This behaviour then breaks when Kubernetes is deployed (by Rancher) inside an LXC or LXD container. Due to missing kernel (net) namespace privileges, the kube-proxy deployment fails and halts the Kubernetes deployment.
Deployment of Kubernetes in a virtual machine (VMware, Virtualbox, KVM, etc) usually works because the VM Hypervisor emulates a virtual hardware for the virtual machine. Inside the VM a full OS is installed, including its very own Linux Kernel and the Kernel modules. The OS inside the VM has full control over all Kernel parameters (sysctl for example).
However inside a container, whether this is LXC or Docker, the surroundings are different. There is no virtual hardware emulated around the OS - and even the OS is basically a "chrooted" directory, using (and sharing) the Kernel with the host. For security reasons containers are only allowed to change certain settings inside their own namespace. And this is where the problem with Kubernetes hits; it wants to change Kernel settings which belong to the container's host.
There are a couple of tutorials available which mention that Kubernetes works inside LXD containers. A very good tutorial can be found on GitHub, written by Cornelius Weig.
The requirements to do lay the foundation for running Kubernetes inside LXD are:
This results in a LXD profile (named k8s) such as this:
root@host ~ # lxc profile show k8s
config:
limits.cpu: "4"
limits.memory: 4GB
limits.memory.swap: "false"
linux.kernel_modules: ip_tables,ip6_tables,nf_nat,overlay,br_netfilter
raw.lxc: "lxc.apparmor.profile=unconfined\nlxc.cap.drop= \nlxc.cgroup.devices.allow=a\nlxc.mount.auto=proc:rw
sys:rw"
security.nesting: "true"
security.privileged: "true"
description: Kubernetes Lab Profile
devices:
eth0:
name: eth0
nictype: bridged
parent: virbr0
type: nic
root:
path: /
pool: default
type: disk
name: k8s
used_by: []
But even this is not enough.
Once the LXD containers are created and started, the container's filesystem needs to be mounted as shared filesystem (see Kubernetes cluster provisioning fails with error response / is not a shared mount). This can be handled by using the /etc/rc.local file (create the file if it doesn't exist):
root@lxdcontainer:~# cat /etc/rc.local
#!/bin/bash
mount --make-shared /
exit
Make /etc/rc.local executable and the Systemd service rc-local should then take care of this file (see /etc/rc.local does not exist anymore).
root@lxdcontainer:~# chmod 755 /etc/rc.local
root@lxdcontainer:~# systemctl restart rc-local
And if this wouldn't be enough, recent Kubernetes versions now also require to have a /dev/kmsg device node available in the OS, so this needs to be created as well. In this case, the device node can be created as a symlink by systemd's tmpfiles.d:
root@lxdcontainer:~# echo 'L /dev/kmsg - - - - /dev/null' > /etc/tmpfiles.d/kmsg.conf
Reboot the LXD container afterwards.
When a new Kubernetes cluster in Rancher is created, it awaits the deployments of Kubernetes inside the nodes. So let's take this created lxdcontainer and fire up the Kubernetes deployment with the docker run command seen in Rancher's user interface:
root@lxdcontainer:~# sudo docker run -d --privileged --restart=unless-stopped --net=host -v /etc/kubernetes:/etc/kubernetes -v /var/run:/var/run rancher/rancher-agent:v2.5.9 --server https://rancher.example.com --token lpk4b444vb7xcwtn4qpdpqv964n4rtlvbfm2xcjkkq75gjg9jzn4kq --ca-checksum 449144c1445882641ff0d66593c5a1fc2eb0fa90994e95eb46efe0b341317afa --etcd --controlplane --worker
But then after a while the reality kicks in: The cluster deployment is stuck on kube-proxy. The Rancher server logs (and the user interface) shows the following error:
2021/07/23 07:40:55 [ERROR] Failed to upgrade worker components on NotReady hosts, error: [Failed to verify healthcheck: Failed to check http://localhost:10256/healthz for service [kube-proxy] on host [192.168.15.161]: Get "http://localhost:10256/healthz": dial tcp 127.0.0.1:10256: connect: connection refused, log: F0723 07:40:32.920751 19619 server.go:495] open /proc/sys/net/netfilter/nf_conntrack_max: permission denied]
A closer look into the kube-proxy container logs reveals that it tried to set a different value for the nf_conntrack_max Kernel setting:
root@lxdcontainer:~# docker logs --follow kube-proxy
[...]
W0723 07:30:08.920852 12314 server.go:226] WARNING: all flags other than --config, --write-config-to, and --cleanup are deprecated. Please begin using a config file ASAP.
I0723 07:30:08.920930 12314 feature_gate.go:243] feature gates: &{map[]}
I0723 07:30:08.921038 12314 feature_gate.go:243] feature gates: &{map[]}
W0723 07:30:08.921571 12314 proxier.go:651] Failed to read file /lib/modules/5.10.0-0.bpo.7-amd64/modules.builtin with error open /lib/modules/5.10.0-0.bpo.7-amd64/modules.builtin: no such file or directory. You can ignore this message when kube-proxy is running inside container without mounting /lib/modules
W0723 07:30:08.923115 12314 proxier.go:661] Failed to load kernel module ip_vs with modprobe. You can ignore this message when kube-proxy is running inside container without mounting /lib/modules
W0723 07:30:08.924299 12314 proxier.go:661] Failed to load kernel module ip_vs_rr with modprobe. You can ignore this message when kube-proxy is running inside container without mounting /lib/modules
W0723 07:30:08.925830 12314 proxier.go:661] Failed to load kernel module ip_vs_wrr with modprobe. You can ignore this message when kube-proxy is running inside container without mounting /lib/modules
W0723 07:30:08.927054 12314 proxier.go:661] Failed to load kernel module ip_vs_sh with modprobe. You can ignore this message when kube-proxy is running inside container without mounting /lib/modules
W0723 07:30:08.928042 12314 proxier.go:661] Failed to load kernel module nf_conntrack with modprobe. You can ignore this message when kube-proxy is running inside container without mounting /lib/modules
I0723 07:30:08.943595 12314 node.go:172] Successfully retrieved node IP: 172.17.0.1
I0723 07:30:08.943627 12314 server_others.go:142] kube-proxy node IP is an IPv4 address (172.17.0.1), assume IPv4 operation
W0723 07:30:08.944553 12314 server_others.go:584] Unknown proxy mode "", assuming iptables proxy
I0723 07:30:08.944629 12314 server_others.go:182] DetectLocalMode: 'ClusterCIDR'
I0723 07:30:08.944652 12314 server_others.go:185] Using iptables Proxier.
I0723 07:30:08.944760 12314 proxier.go:287] iptables(IPv4) masquerade mark: 0x00004000
I0723 07:30:08.944857 12314 proxier.go:334] iptables(IPv4) sync params: minSyncPeriod=1s, syncPeriod=30s, burstSyncs=2
I0723 07:30:08.944977 12314 proxier.go:346] iptables(IPv4) supports --random-fully
I0723 07:30:08.945162 12314 server.go:650] Version: v1.20.8
I0723 07:30:08.945589 12314 conntrack.go:100] Set sysctl 'net/netfilter/nf_conntrack_max' to 131072
F0723 07:30:08.945634 12314 server.go:495] open /proc/sys/net/netfilter/nf_conntrack_max: permission denied
The LXD container (lxdcontainer) has no privileges to change this setting as it comes from the host:
root@lxdcontainer:~# sysctl -w net.netfilter.nf_conntrack_max=131072
sysctl: setting key "net.netfilter.nf_conntrack_max"
root@lxdcontainer:~# sysctl -a |grep nf_conntrack_max
net.netfilter.nf_conntrack_max = 524288
The value remains at the host-given value.
The reason for this seems to be a changed behaviour in the Linux Kernel (since 4.10), disallowing non init network namespaces to change these settings (the network of the LXD container was not initiated inside the container's namespace, therefore it is not considered a network initiating namespace).
What is very annoying however is the following fact: The existing value is set to 524288 - which is higher than what kube-proxy wants to set: 131072. Why would kube-proxy bother to set nf_conntrack_max to a specific value, when a currently higher value is already defined?
At first a bug inside Rancher itself was assumed. A similar problem also happens when Rancher (the application) itself is deployed as single docker installation and the value is changed after the initial installation. Hence issue #33360 was created in the Rancher repositories. Deeper analysis revealed that this problem occurs inside the conntrack.go file, which is part of the kube-proxy application:
func (realConntracker) setIntSysCtl(name string, value int) error {
entry := "net/netfilter/" + name
sys := sysctl.New()
if val, _ := sys.GetSysctl(entry); val != value {
klog.Infof("Set sysctl '%v' to %v", entry, value)
if err := sys.SetSysctl(entry, value); err != nil {
return err
}
}
return nil
}
Here we can see an if condition which compares the current system value (val) with the (internally) expected value (value). If they don't match, the function sys.SetSysctl is launched and then tries to set a new value for the setting.
As mentioned before, this would make sense when Kubernetes requires a minimum value but the current system value is lower than that minimum. However when the system value is higher than the expected value, Kubernetes should just accept this and move on. This is the basic description of the Kubernetes Pull Request #103174, which should cover that "workaround".
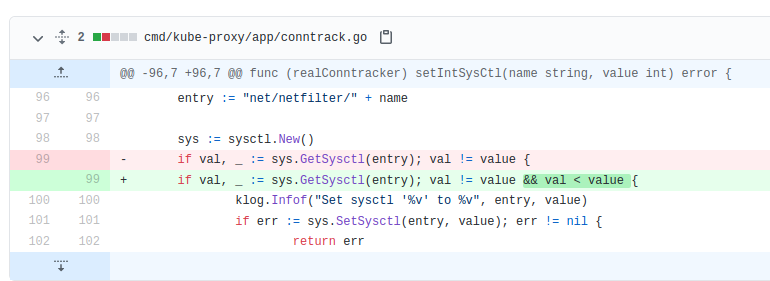
Once this PR gets merged into the kube-proxy code, a situation like this should just be ignored and kube-proxy deployment won't be stuck anymore - ergo Rancher Kubernetes deployment continues.
Let's keep the fingers crossed that this PR soon makes it into Kubernetes and then also into a newer Rancher release.
By the way: Other workarounds which go into the exact same direction are already in place, however only for the nf_conntrack_hashsize setting. Looking at the very same conntrack.go file shows the following comment:
// Linux does not support writing to /sys/module/nf_conntrack/parameters/hashsize
// when the writer process is not in the initial network namespace
// (https://github.com/torvalds/linux/blob/v4.10/net/netfilter/nf_conntrack_core.c#L1795-L1796).
// Usually that's fine. But in some configurations such as with github.com/kinvolk/kubeadm-nspawn,
// kube-proxy is in another netns.
// Therefore, check if writing in hashsize is necessary and skip the writing if not.
hashsize, err := readIntStringFile("/sys/module/nf_conntrack/parameters/hashsize")
if err != nil {
return err
}
if hashsize >= (max / 4) {
return nil
}
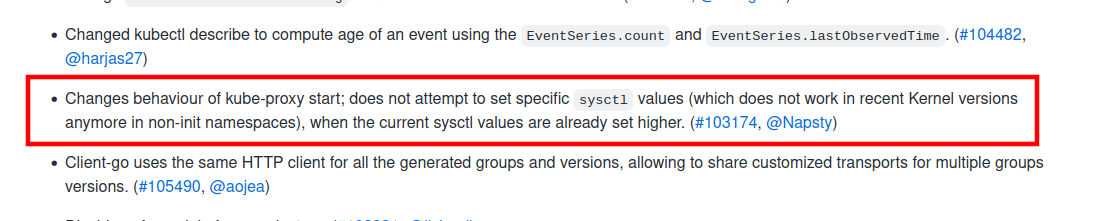
Great news! The mentioned Kubernetes Pull Request has now been merged with a milestone of 1.23. That means that starting with Kubernetes 1.23, kube-proxy should be able to start in containers running recent Kernel versions. As long as the current Kernel sysctl values are equal or higher than what Kubernetes is expected, this should work. At least seen with Ubuntu 20.04, the defaults are already higher than what kube-proxy attempts to set.
Update December 8th 2021
Kubernetes 1.23, code-named The Next Frontier, was released yesterday, on December 7th 2021. The changelog also includes the changes in kube-proxy.
No comments yet.

AI AWS Android Ansible Apache Apple Atlassian BSD Backup Bash Bluecoat CMS Chef Cloud Coding Consul Containers CouchDB DB DNS Databases Docker ELK Elasticsearch Filebeat FreeBSD Galera Git GlusterFS Grafana Graphics HAProxy HTML Hacks Hardware Icinga Influx Internet Java KVM Kibana Kodi Kubernetes LVM LXC Linux Logstash Mac Macintosh Mail MariaDB Minio MongoDB Monitoring Multimedia MySQL NFS Nagios Network Nginx OSSEC OTRS Observability Office OpenSearch PHP Perl Personal PostgreSQL PowerDNS Proxmox Proxy Python Rancher Rant Redis Roundcube SSL Samba Seafile Security Shell SmartOS Solaris Surveillance Systemd TLS Tomcat Ubuntu Unix VMware Varnish Virtualization Windows Wireless Wordpress Wyse ZFS Znuny Zoneminder