
After a "local" Kubernetes cluster (a.k.a. the cluster on which Rancher server runs) was upgraded from 1.18 to 1.20, all kinds of problems started. Pods were not created nor deleted anymore, the workloads in the whole "System" project were stuck in deployment.
In Rancher 2, the "local" cluster is the Kubernetes management cluster. It hosts the Rancher server itself, managing the so-called "downstream clusters". The most current way to upgrade Kubernetes on the Rancher local cluster is to use RKE.
In the following example, RKE 1.3.1 was used to upgrade Kubernetes from the previous 1.18.15 to 1.20.11:
ck@mgmt:~/rancher$ grep kubernetes_version RANCHER-n12/3-node-rancher-cluster.yml
#kubernetes_version: "v1.18.15-rancher1-1"
kubernetes_version: "v1.20.11-rancher1-2"
ck@mgmt:~/rancher$ ./rke_linux-amd64-1.3.1 up --config RANCHER2-n12/3-node-rancher-cluster.yml
INFO[0000] Running RKE version: v1.3.1
INFO[0000] Initiating Kubernetes cluster
INFO[0000] [certificates] GenerateServingCertificate is disabled, checking if there are unused kubelet certificates
INFO[0000] [certificates] Generating admin certificates and kubeconfig
INFO[0000] Successfully Deployed state file at [RANCHER2-n12/3-node-rancher-cluster.rkestate]
INFO[0000] Building Kubernetes cluster
[...]
INFO[0450] [addons] Executing deploy job rke-ingress-controller
INFO[0525] [ingress] ingress controller nginx deployed successfully
INFO[0525] [addons] Setting up user addons
INFO[0529] [addons] no user addons defined
INFO[0529] Finished building Kubernetes cluster successfully
This might take quite a while, but eventually (should) finish successfully.
However after the upgrade, the Rancher user interface obviously had problems. A lot of health check failures were noticed in the load balancer. This situation endured around 30 minutes until finally the cluster nodes seemed to be stable - at least for the Rancher UI.
Once in the UI, the "System" project of the local cluster was verified. We've found a lot of deployments in the kube-system namespace either red (failed or unavailable) or stuck in deployment:
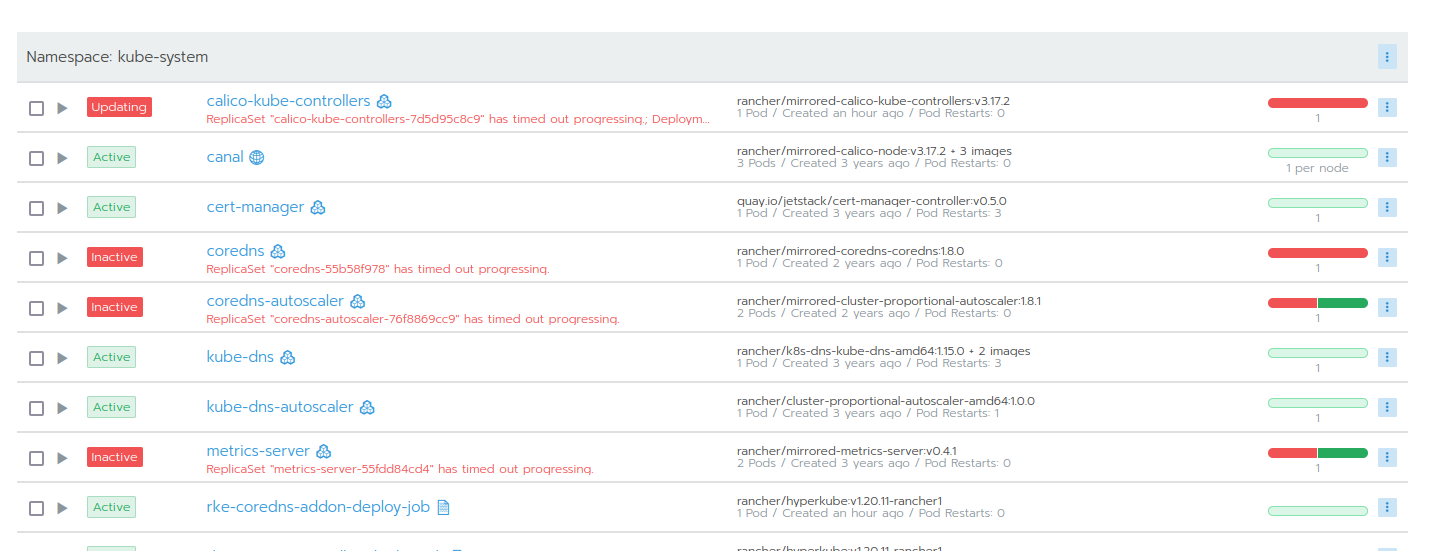
Manual deletion of the stuck containers had no effect either. Time for troubleshooting!
The kubelet container on one of the cluster nodes showed very interesting errors in the logs:
root@node3:~# docker logs --tail 20 --follow kubelet
W1026 13:18:27.501306 15522 cni.go:333] CNI failed to retrieve network namespace path: cannot find network namespace for the terminated container "1be6321e20231489ad2ddf114d9e132f19510164ca1cde6794cd810036a84c85"
E1026 13:18:27.556138 15522 cni.go:387] Error deleting kube-system_coredns-55b58f978-f64xn/1be6321e20231489ad2ddf114d9e132f19510164ca1cde6794cd810036a84c85 from network calico/k8s-pod-network: error getting ClusterInformation: connection is unauthorized: clusterinformations.crd.projectcalico.org "default" is forbidden: User "system:node" cannot get resource "clusterinformations" in API group "crd.projectcalico.org" at the cluster scope: RBAC: clusterrole.rbac.authorization.k8s.io "calico-node" not found
E1026 13:18:27.557006 15522 remote_runtime.go:143] StopPodSandbox "1be6321e20231489ad2ddf114d9e132f19510164ca1cde6794cd810036a84c85" from runtime service failed: rpc error: code = Unknown desc = networkPlugin cni failed to teardown pod "coredns-55b58f978-f64xn_kube-system" network: error getting ClusterInformation: connection is unauthorized: clusterinformations.crd.projectcalico.org "default" is forbidden: User "system:node" cannot get resource "clusterinformations" in API group "crd.projectcalico.org" at the cluster scope: RBAC: clusterrole.rbac.authorization.k8s.io "calico-node" not found
E1026 13:18:27.557064 15522 kuberuntime_manager.go:923] Failed to stop sandbox {"docker" "1be6321e20231489ad2ddf114d9e132f19510164ca1cde6794cd810036a84c85"}
E1026 13:18:27.557170 15522 kuberuntime_manager.go:702] killPodWithSyncResult failed: failed to "KillPodSandbox" for "cff27adb-8df8-4324-b814-9b7dfdf7c732" with KillPodSandboxError: "rpc error: code = Unknown desc = networkPlugin cni failed to teardown pod \"coredns-55b58f978-f64xn_kube-system\" network: error getting ClusterInformation: connection is unauthorized: clusterinformations.crd.projectcalico.org \"default\" is forbidden: User \"system:node\" cannot get resource \"clusterinformations\" in API group \"crd.projectcalico.org\" at the cluster scope: RBAC: clusterrole.rbac.authorization.k8s.io \"calico-node\" not found"
E1026 13:18:27.557199 15522 pod_workers.go:191] Error syncing pod cff27adb-8df8-4324-b814-9b7dfdf7c732 ("coredns-55b58f978-f64xn_kube-system(cff27adb-8df8-4324-b814-9b7dfdf7c732)"), skipping: failed to "KillPodSandbox" for "cff27adb-8df8-4324-b814-9b7dfdf7c732" with KillPodSandboxError: "rpc error: code = Unknown desc = networkPlugin cni failed to teardown pod \"coredns-55b58f978-f64xn_kube-system\" network: error getting ClusterInformation: connection is unauthorized: clusterinformations.crd.projectcalico.org \"default\" is forbidden: User \"system:node\" cannot get resource \"clusterinformations\" in API group \"crd.projectcalico.org\" at the cluster scope: RBAC: clusterrole.rbac.authorization.k8s.io \"calico-node\" not found"
I1026 13:18:34.499501 15522 kuberuntime_manager.go:469] Sandbox for pod "rancher-57c5454b95-v4m8g_cattle-system(f3575fc7-5611-41e6-8aad-93b06cfbc926)" has no IP address. Need to start a new one
W1026 13:18:34.501370 15522 cni.go:333] CNI failed to retrieve network namespace path: cannot find network namespace for the terminated container "3cf06311a8112cc97249742d898899a916aa71a55cf5881b7721a88371e4bdbc"
E1026 13:18:34.602698 15522 cni.go:387] Error deleting cattle-system_rancher-57c5454b95-v4m8g/3cf06311a8112cc97249742d898899a916aa71a55cf5881b7721a88371e4bdbc from network calico/k8s-pod-network: error getting ClusterInformation: connection is unauthorized: clusterinformations.crd.projectcalico.org "default" is forbidden: User "system:node" cannot get resource "clusterinformations" in API group "crd.projectcalico.org" at the cluster scope: RBAC: clusterrole.rbac.authorization.k8s.io "calico-node" not found
E1026 13:18:34.603702 15522 remote_runtime.go:143] StopPodSandbox "3cf06311a8112cc97249742d898899a916aa71a55cf5881b7721a88371e4bdbc" from runtime service failed: rpc error: code = Unknown desc = networkPlugin cni failed to teardown pod "rancher-57c5454b95-v4m8g_cattle-system" network: error getting ClusterInformation: connection is unauthorized: clusterinformations.crd.projectcalico.org "default" is forbidden: User "system:node" cannot get resource "clusterinformations" in API group "crd.projectcalico.org" at the cluster scope: RBAC: clusterrole.rbac.authorization.k8s.io "calico-node" not found
[...]
According to the logs, CNI (Container Network Interface) was unable to retrieve needed information from the Kubernetes API due to missing authorization. But how could this happen? How did this work before?
Research led to a currently open issue #2527 in Rancher's RKE GitHub repositories. The reporting user ran into the same problem - also on a cluster which was previously upgraded from an older Kubernetes version. After a couple of minutes of further research, we came across a thread in the Rancher forums, pointing to the same RBAC authorization problems after a Kubernetes upgrade to 1.19. User wech71 commented that he was able to solve the problem by manually (re-)applying the calico-node cluster role.
Calico, which is (very basically explained) the role for managing network inside the Kubernetes cluster, requires a certain cluster role called "calico-node" in Kubernetes. To verify this, the full Calico CNI deployment can be downloaded - however this YAML file contains more than what is needed for this. By going through the yaml config, the relevant part can be found after the line "# Source: calico/templates/calico-node-rbac.yaml":
---
# Source: calico/templates/calico-node-rbac.yaml
# Include a clusterrole for the calico-node DaemonSet,
# and bind it to the calico-node serviceaccount.
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: calico-node
rules:
# The CNI plugin needs to get pods, nodes, and namespaces.
[...]
Here the name of this ClusterRole is defined as calico-node. A manual check of the existing cluster roles reveals that this role is missing:
ck@mgmt:~/rancher$ kubectl get ClusterRole | grep -i calico
calico 2018-11-07T11:20:30Z
calico-kube-controllers 2021-10-26T12:27:34Z
On the other hand, a role "calico" exists in this Kubernetes cluster - but no "calico-node" role. As this cluster is quite old (2018-11-07), as one can see from the output, we assume that the role name has changed at some Kubernetes or Calico version; now causing problems in a newer Kubernetes version. RKE should have probably checked whether or not this role exists - but waiting weeks for a fix in RKE doesn't help our current situation. We need to fix the cluster now.
By saving the "ClusterRole" part from the full yaml file into a separate file, we can now run kubectl to deploy this cluster role into the Kubernetes API:
ck@mgmt:~/rancher$ cat calico-node-rbac.yaml
---
# Source: calico/templates/calico-node-rbac.yaml
# Include a clusterrole for the calico-node DaemonSet,
# and bind it to the calico-node serviceaccount.
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: calico-node
rules:
# The CNI plugin needs to get pods, nodes, and namespaces.
- apiGroups: [""]
resources:
- pods
- nodes
- namespaces
verbs:
- get
# EndpointSlices are used for Service-based network policy rule
# enforcement.
- apiGroups: ["discovery.k8s.io"]
resources:
- endpointslices
verbs:
- watch
- list
- apiGroups: [""]
resources:
- endpoints
- services
verbs:
# Used to discover service IPs for advertisement.
- watch
- list
# Used to discover Typhas.
- get
# Pod CIDR auto-detection on kubeadm needs access to config maps.
- apiGroups: [""]
resources:
- configmaps
verbs:
- get
- apiGroups: [""]
resources:
- nodes/status
verbs:
# Needed for clearing NodeNetworkUnavailable flag.
- patch
# Calico stores some configuration information in node annotations.
- update
# Watch for changes to Kubernetes NetworkPolicies.
- apiGroups: ["networking.k8s.io"]
resources:
- networkpolicies
verbs:
- watch
- list
# Used by Calico for policy information.
- apiGroups: [""]
resources:
- pods
- namespaces
- serviceaccounts
verbs:
- list
- watch
# The CNI plugin patches pods/status.
- apiGroups: [""]
resources:
- pods/status
verbs:
- patch
# Calico monitors various CRDs for config.
- apiGroups: ["crd.projectcalico.org"]
resources:
- globalfelixconfigs
- felixconfigurations
- bgppeers
- globalbgpconfigs
- bgpconfigurations
- ippools
- ipamblocks
- globalnetworkpolicies
- globalnetworksets
- networkpolicies
- networksets
- clusterinformations
- hostendpoints
- blockaffinities
verbs:
- get
- list
- watch
# Calico must create and update some CRDs on startup.
- apiGroups: ["crd.projectcalico.org"]
resources:
- ippools
- felixconfigurations
- clusterinformations
verbs:
- create
- update
# Calico stores some configuration information on the node.
- apiGroups: [""]
resources:
- nodes
verbs:
- get
- list
- watch
# These permissions are only required for upgrade from v2.6, and can
# be removed after upgrade or on fresh installations.
- apiGroups: ["crd.projectcalico.org"]
resources:
- bgpconfigurations
- bgppeers
verbs:
- create
- update
Note: Use the newest calico version from the download link above, not this excerpt!
ck@mgmt:~/rancher$ kubectl auth reconcile -f calico-node-rbac.yaml
clusterrole.rbac.authorization.k8s.io/calico-node reconciled
reconciliation required create
missing rules added:
{Verbs:[get] APIGroups:[] Resources:[pods nodes namespaces] ResourceNames:[] NonResourceURLs:[]}
{Verbs:[watch list] APIGroups:[discovery.k8s.io] Resources:[endpointslices] ResourceNames:[] NonResourceURLs:[]}
{Verbs:[watch list get] APIGroups:[] Resources:[endpoints services] ResourceNames:[] NonResourceURLs:[]}
{Verbs:[get] APIGroups:[] Resources:[configmaps] ResourceNames:[] NonResourceURLs:[]}
{Verbs:[patch update] APIGroups:[] Resources:[nodes/status] ResourceNames:[] NonResourceURLs:[]}
{Verbs:[watch list] APIGroups:[networking.k8s.io] Resources:[networkpolicies] ResourceNames:[] NonResourceURLs:[]}
{Verbs:[list watch] APIGroups:[] Resources:[pods namespaces serviceaccounts] ResourceNames:[] NonResourceURLs:[]}
{Verbs:[patch] APIGroups:[] Resources:[pods/status] ResourceNames:[] NonResourceURLs:[]}
{Verbs:[get list watch] APIGroups:[crd.projectcalico.org] Resources:[globalfelixconfigs felixconfigurations bgppeers globalbgpconfigs bgpconfigurations ippools ipamblocks globalnetworkpolicies globalnetworksets networkpolicies networksets clusterinformations hostendpoints blockaffinities] ResourceNames:[] NonResourceURLs:[]}
{Verbs:[create update] APIGroups:[crd.projectcalico.org] Resources:[ippools felixconfigurations clusterinformations] ResourceNames:[] NonResourceURLs:[]}
{Verbs:[get list watch] APIGroups:[] Resources:[nodes] ResourceNames:[] NonResourceURLs:[]}
{Verbs:[create update] APIGroups:[crd.projectcalico.org] Resources:[bgpconfigurations bgppeers] ResourceNames:[] NonResourceURLs:[]}
The output confirms: A lot of missing rules have been added in the Kubernetes cluster!
Checking the cluster roles once more, the calico-node role can now be found:
ck@mgmt:~/rancher$ kubectl get ClusterRole | grep -i calico
calico 2018-11-07T11:20:30Z
calico-kube-controllers 2021-10-26T12:27:34Z
calico-node 2021-10-26T13:23:08Z
Shortly after the calico-node role was applied to the Kubernetes cluster, the (previously stuck) workloads started to move again. The same kubelet container on node3 now shows completely different logs:
root@node3:~# docker logs --tail 20 --follow kubelet
I1026 13:23:24.425522 15522 kubelet.go:1952] SyncLoop (PLEG): "rancher-57c5454b95-v4m8g_cattle-system(f3575fc7-5611-41e6-8aad-93b06cfbc926)", event: &pleg.PodLifecycleEvent{ID:"f3575fc7-5611-41e6-8aad-93b06cfbc926", Type:"ContainerStarted", Data:"052c7a0d610b4a57d309afa7f9fdb6ebe16f9e2c84ae2260d165afd1ea36885e"}
I1026 13:23:24.580957 15522 kubelet.go:1930] SyncLoop (DELETE, "api"): "coredns-autoscaler-5dcd676cbd-prmpq_kube-system(1f7b08e4-65f3-49d5-9e0e-7e9e3dda01a1)"
I1026 13:23:24.581585 15522 kuberuntime_container.go:635] Killing container "docker://e5615b75f545936e0ef5d5fb11462e98a38de83abe8bbcefacbbdf3caff49f0f" with a 30 second grace period
I1026 13:23:25.649488 15522 kubelet.go:1930] SyncLoop (DELETE, "api"): "coredns-autoscaler-5dcd676cbd-prmpq_kube-system(1f7b08e4-65f3-49d5-9e0e-7e9e3dda01a1)"
I1026 13:23:26.477908 15522 kubelet.go:1952] SyncLoop (PLEG): "coredns-autoscaler-5dcd676cbd-prmpq_kube-system(1f7b08e4-65f3-49d5-9e0e-7e9e3dda01a1)", event: &pleg.PodLifecycleEvent{ID:"1f7b08e4-65f3-49d5-9e0e-7e9e3dda01a1", Type:"ContainerDied", Data:"e5615b75f545936e0ef5d5fb11462e98a38de83abe8bbcefacbbdf3caff49f0f"}
I1026 13:23:26.478034 15522 kubelet.go:1952] SyncLoop (PLEG): "coredns-autoscaler-5dcd676cbd-prmpq_kube-system(1f7b08e4-65f3-49d5-9e0e-7e9e3dda01a1)", event: &pleg.PodLifecycleEvent{ID:"1f7b08e4-65f3-49d5-9e0e-7e9e3dda01a1", Type:"ContainerDied", Data:"eb0d485b9419ef1a59d244f4db88b63ffa13b0f7471d594cec472b2c547116bb"}
I1026 13:23:26.478117 15522 scope.go:111] [topologymanager] RemoveContainer - Container ID: e5615b75f545936e0ef5d5fb11462e98a38de83abe8bbcefacbbdf3caff49f0f
I1026 13:23:26.598850 15522 reconciler.go:196] operationExecutor.UnmountVolume started for volume "coredns-autoscaler-token-d2h2q" (UniqueName: "kubernetes.io/secret/1f7b08e4-65f3-49d5-9e0e-7e9e3dda01a1-coredns-autoscaler-token-d2h2q") pod "1f7b08e4-65f3-49d5-9e0e-7e9e3dda01a1" (UID: "1f7b08e4-65f3-49d5-9e0e-7e9e3dda01a1")
I1026 13:23:26.635813 15522 operation_generator.go:797] UnmountVolume.TearDown succeeded for volume "kubernetes.io/secret/1f7b08e4-65f3-49d5-9e0e-7e9e3dda01a1-coredns-autoscaler-token-d2h2q" (OuterVolumeSpecName: "coredns-autoscaler-token-d2h2q") pod "1f7b08e4-65f3-49d5-9e0e-7e9e3dda01a1" (UID: "1f7b08e4-65f3-49d5-9e0e-7e9e3dda01a1"). InnerVolumeSpecName "coredns-autoscaler-token-d2h2q". PluginName "kubernetes.io/secret", VolumeGidValue ""
I1026 13:23:26.677839 15522 scope.go:111] [topologymanager] RemoveContainer - Container ID: e5615b75f545936e0ef5d5fb11462e98a38de83abe8bbcefacbbdf3caff49f0f
E1026 13:23:26.692515 15522 remote_runtime.go:332] ContainerStatus "e5615b75f545936e0ef5d5fb11462e98a38de83abe8bbcefacbbdf3caff49f0f" from runtime service failed: rpc error: code = Unknown desc = Error: No such container: e5615b75f545936e0ef5d5fb11462e98a38de83abe8bbcefacbbdf3caff49f0f
W1026 13:23:26.692584 15522 pod_container_deletor.go:52] [pod_container_deletor] DeleteContainer returned error for (id={docker e5615b75f545936e0ef5d5fb11462e98a38de83abe8bbcefacbbdf3caff49f0f}): failed to get container status "e5615b75f545936e0ef5d5fb11462e98a38de83abe8bbcefacbbdf3caff49f0f": rpc error: code = Unknown desc = Error: No such container: e5615b75f545936e0ef5d5fb11462e98a38de83abe8bbcefacbbdf3caff49f0f
I1026 13:23:26.699172 15522 reconciler.go:319] Volume detached for volume "coredns-autoscaler-token-d2h2q" (UniqueName: "kubernetes.io/secret/1f7b08e4-65f3-49d5-9e0e-7e9e3dda01a1-coredns-autoscaler-token-d2h2q") on node "192.168.253.17" DevicePath ""
I1026 13:23:26.989381 15522 container_manager_linux.go:490] [ContainerManager]: Discovered runtime cgroups name: /system.slice/docker.service
I1026 13:23:35.543271 15522 kube_docker_client.go:344] Pulling image "rancher/rancher:v2.5.10": "fd7a9568ccc6: Extracting [==================================================>] 341B/341B"
I1026 13:23:36.559195 15522 kubelet.go:1930] SyncLoop (DELETE, "api"): "coredns-autoscaler-5dcd676cbd-prmpq_kube-system(1f7b08e4-65f3-49d5-9e0e-7e9e3dda01a1)"
I1026 13:23:36.569181 15522 kubelet.go:1924] SyncLoop (REMOVE, "api"): "coredns-autoscaler-5dcd676cbd-prmpq_kube-system(1f7b08e4-65f3-49d5-9e0e-7e9e3dda01a1)"
I1026 13:23:36.569216 15522 kubelet.go:2113] Failed to delete pod "coredns-autoscaler-5dcd676cbd-prmpq_kube-system(1f7b08e4-65f3-49d5-9e0e-7e9e3dda01a1)", err: pod not found
W1026 13:23:38.542570 15522 kubelet_volumes.go:140] Cleaned up orphaned pod volumes dir from pod "1f7b08e4-65f3-49d5-9e0e-7e9e3dda01a1" at /var/lib/kubelet/pods/1f7b08e4-65f3-49d5-9e0e-7e9e3dda01a1/volumes
I1026 13:23:45.498521 15522 kube_docker_client.go:344] Pulling image "rancher/rancher:v2.5.10": "03244223b391: Extracting [===============> ] 8.552MB/27.79MB"
W1026 13:23:49.921838 15522 cni.go:333] CNI failed to retrieve network namespace path: cannot find network namespace for the terminated container "28f20815ae14071980809c91748e8447da734fd858fe87b02f63bcb9299d98d2"
2021-10-26 13:23:50.056 [WARNING][7779] k8s.go 516: WorkloadEndpoint does not exist in the datastore, moving forward with the clean up ContainerID="28f20815ae14071980809c91748e8447da734fd858fe87b02f63bcb9299d98d2" WorkloadEndpoint="192.168.253.17-k8s-coredns--55b58f978--tw9hs-eth0"
W1026 13:23:51.146719 15522 cni.go:333] CNI failed to retrieve network namespace path: cannot find network namespace for the terminated container "dbb19f7797685e752c826d19e3f782deae4bc318975cdcf9ad4d316ed30c37d2"
2021-10-26 13:23:51.228 [WARNING][7813] k8s.go 516: WorkloadEndpoint does not exist in the datastore, moving forward with the clean up ContainerID="dbb19f7797685e752c826d19e3f782deae4bc318975cdcf9ad4d316ed30c37d2" WorkloadEndpoint="192.168.253.17-k8s-default--http--backend--5bcc9fd598--vsdr4-eth0"
W1026 13:23:52.326787 15522 cni.go:333] CNI failed to retrieve network namespace path: cannot find network namespace for the terminated container "cc2a130768745bf6329f640324348f1b14fa69934d6446e0717c9c163ca4c27d"
2021-10-26 13:23:52.455 [WARNING][7854] k8s.go 516: WorkloadEndpoint does not exist in the datastore, moving forward with the clean up ContainerID="cc2a130768745bf6329f640324348f1b14fa69934d6446e0717c9c163ca4c27d" WorkloadEndpoint="192.168.253.17-k8s-calico--kube--controllers--7d5d95c8c9--prmgt-eth0"
W1026 13:23:52.742330 15522 cni.go:333] CNI failed to retrieve network namespace path: cannot find network namespace for the terminated container "b978b07a560903147f203d05ae2524ca55f6c222dc1aa17eb5d79dee73228e5e"
2021-10-26 13:23:52.831 [WARNING][7895] k8s.go 516: WorkloadEndpoint does not exist in the datastore, moving forward with the clean up ContainerID="b978b07a560903147f203d05ae2524ca55f6c222dc1aa17eb5d79dee73228e5e" WorkloadEndpoint="192.168.253.17-k8s-coredns--autoscaler--76f8869cc9--2cnjs-eth0"
[...]
As the output shows, containers are correctly deleted and created again. This situation took on for another couple of minutes - until finally all workloads were correctly deployed on all cluster nodes:
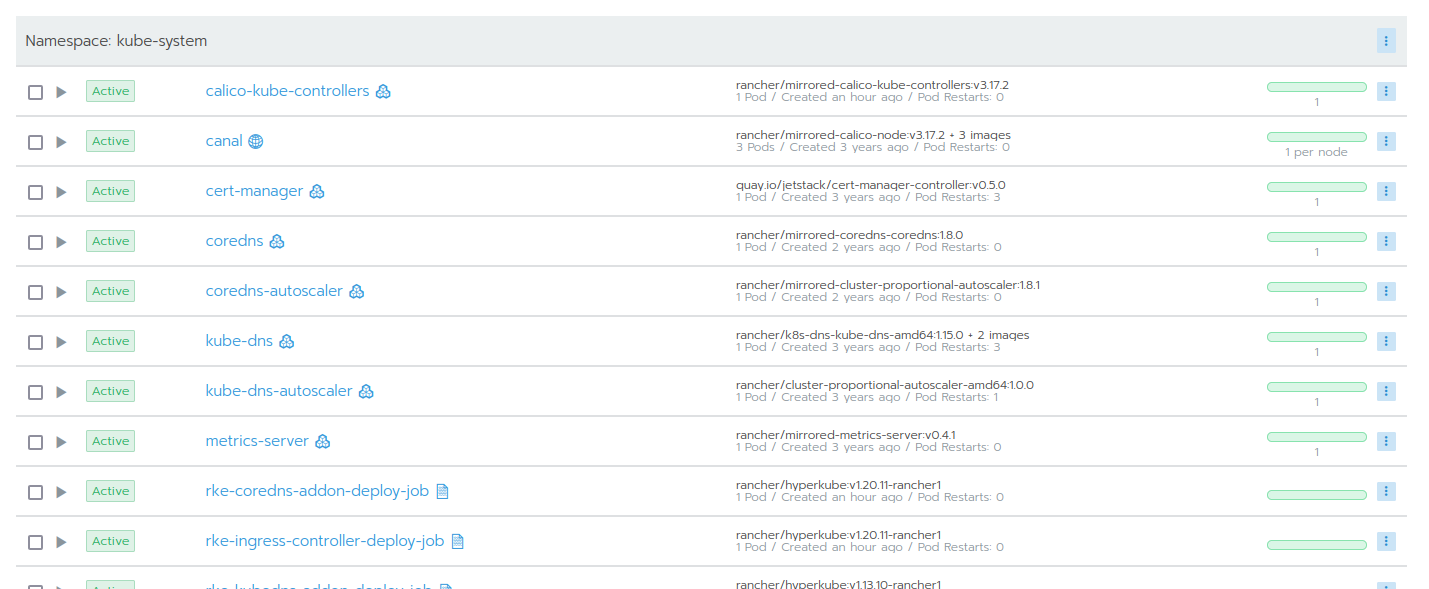
Kubernetes clusters which are created from the Rancher UI, and therefore managed by Rancher, are called "downstream clusters". Depending on the age of these downstream clusters, the very same problem with a missing calico-node role might happen.
The first created downstream cluster of this Rancher environment had more or less the same age as this Rancher setup. And right after Kubernetes was upgraded from 1.18 to 1.20 on November 24th at 3pm (15:00), errors with "connection is unauthorized" started to appear in the downstream cluster. The following screenshot from a centralized log collector (using ELK) shows the effect pretty well:
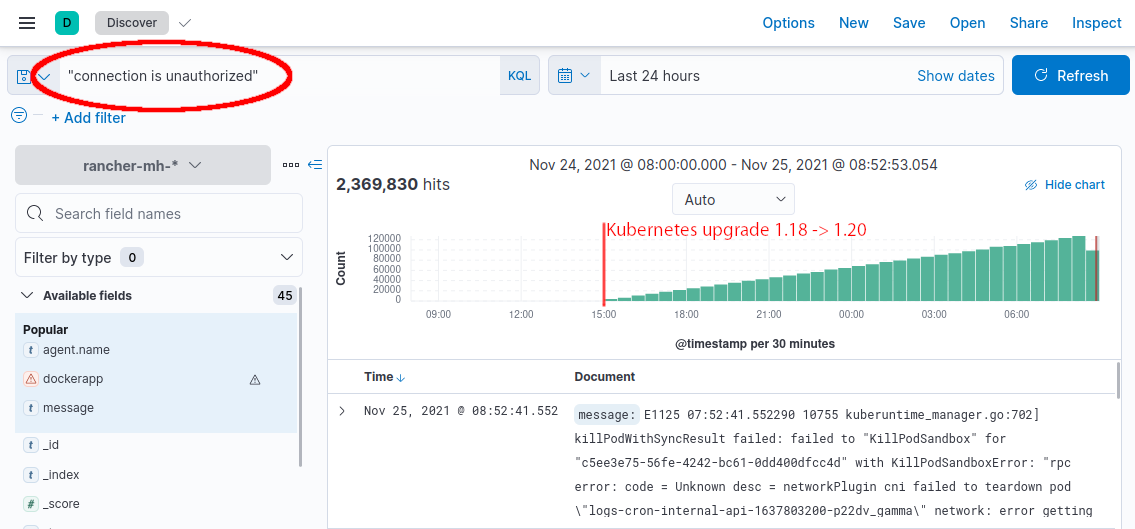
These logs were collected from the "kubelet" container, which is responsible for executing Kubernetes-internal tasks. Looking closer at the kubelet container, reveals the same errors as in the Rancher "local" cluster:
root@downstram-node-1:~# docker logs --tail 20 --follow kubelet
[...]
E1125 08:02:50.016017 14807 cni.go:387] Error deleting gamma_logs-cron-internal-api-1637811300-hlhgw/6b7e70c0a59777726f28852d7edac8c60a1c626e17a0f8ca1ca640e94211d852 from network calico/k8s-pod-network: error getting ClusterInformation: connection is unauthorized: clusterinformations.crd.projectcalico.org "default" is forbidden: User "system:node" cannot get resource "clusterinformations" in API group "crd.projectcalico.org" at the cluster scope: RBAC: clusterrole.rbac.authorization.k8s.io "calico-node" not found
E1125 08:02:50.016823 14807 remote_runtime.go:143] StopPodSandbox "6b7e70c0a59777726f28852d7edac8c60a1c626e17a0f8ca1ca640e94211d852" from runtime service failed: rpc error: code = Unknown desc = networkPlugin cni failed to teardown pod "logs-cron-internal-api-1637811300-hlhgw_gamma" network: error getting ClusterInformation: connection is unauthorized: clusterinformations.crd.projectcalico.org "default" is forbidden: User "system:node" cannot get resource "clusterinformations" in API group "crd.projectcalico.org" at the cluster scope: RBAC: clusterrole.rbac.authorization.k8s.io "calico-node" not found
E1125 08:02:50.016864 14807 kuberuntime_manager.go:923] Failed to stop sandbox {"docker" "6b7e70c0a59777726f28852d7edac8c60a1c626e17a0f8ca1ca640e94211d852"}
E1125 08:02:50.016906 14807 kuberuntime_manager.go:702] killPodWithSyncResult failed: failed to "KillPodSandbox" for "9598b9c9-e805-4822-aa35-fc6e83c7b514" with KillPodSandboxError: "rpc error: code = Unknown desc = networkPlugin cni failed to teardown pod \"logs-cron-internal-api-1637811300-hlhgw_gamma\" network: error getting ClusterInformation: connection is unauthorized: clusterinformations.crd.projectcalico.org \"default\" is forbidden: User \"system:node\" cannot get resource \"clusterinformations\" in API group \"crd.projectcalico.org\" at the cluster scope: RBAC: clusterrole.rbac.authorization.k8s.io \"calico-node\" not found"
E1125 08:02:50.016951 14807 pod_workers.go:191] Error syncing pod 9598b9c9-e805-4822-aa35-fc6e83c7b514 ("logs-cron-internal-api-1637811300-hlhgw_gamma(9598b9c9-e805-4822-aa35-fc6e83c7b514)"), skipping: failed to "KillPodSandbox" for "9598b9c9-e805-4822-aa35-fc6e83c7b514" with KillPodSandboxError: "rpc error: code = Unknown desc = networkPlugin cni failed to teardown pod \"logs-cron-internal-api-1637811300-hlhgw_gamma\" network: error getting ClusterInformation: connection is unauthorized: clusterinformations.crd.projectcalico.org \"default\" is forbidden: User \"system:node\" cannot get resource \"clusterinformations\" in API group \"crd.projectcalico.org\" at the cluster scope: RBAC: clusterrole.rbac.authorization.k8s.io \"calico-node\" not found"
E1125 08:02:50.024976 14807 cni.go:387] Error deleting gamma_logs-cron-internal-api-1637791500-rhglm/8178bbe10f902c4f244241f30e3010d352ab0b3f759c78cd4b87c45ee86d34f2 from network calico/k8s-pod-network: error getting ClusterInformation: connection is unauthorized: clusterinformations.crd.projectcalico.org "default" is forbidden: User "system:node" cannot get resource "clusterinformations" in API group "crd.projectcalico.org" at the cluster scope: RBAC: clusterrole.rbac.authorization.k8s.io "calico-node" not found
E1125 08:02:50.026079 14807 remote_runtime.go:143] StopPodSandbox "8178bbe10f902c4f244241f30e3010d352ab0b3f759c78cd4b87c45ee86d34f2" from runtime service failed: rpc error: code = Unknown desc = networkPlugin cni failed to teardown pod "logs-cron-internal-api-1637791500-rhglm_gamma" network: error getting ClusterInformation: connection is unauthorized: clusterinformations.crd.projectcalico.org "default" is forbidden: User "system:node" cannot get resource "clusterinformations" in API group "crd.projectcalico.org" at the cluster scope: RBAC: clusterrole.rbac.authorization.k8s.io "calico-node" not found
[...]
The solution is the same as in the "local" cluster: Manually deploy the missing calico-node role with kubectl auth reconcile.
Although currently called "the de-facto container infrastructure", Kubernetes is anything but easy. The complexity adds additional problems and considerations. We at Infiniroot love to share our troubleshooting knowledge when we need to tackle certain issues - but we also know this is not for everyone ("it just needs to work"). So if you are looking for a managed and dedicated Kubernetes environment, managed by Rancher 2, with server location Switzerland, check out our Private Kubernetes Container Cloud Infrastructure service at Infiniroot.
No comments yet.

AI AWS Android Ansible Apache Apple Atlassian BSD Backup Bash Bluecoat CMS Chef Cloud Coding Consul Containers CouchDB DB DNS Databases Docker ELK Elasticsearch Filebeat FreeBSD Galera Git GlusterFS Grafana Graphics HAProxy HTML Hacks Hardware Icinga Influx Internet Java KVM Kibana Kodi Kubernetes LVM LXC Linux Logstash Mac Macintosh Mail MariaDB Minio MongoDB Monitoring Multimedia MySQL NFS Nagios Network Nginx OSSEC OTRS Observability Office OpenSearch PHP Perl Personal PostgreSQL PowerDNS Proxmox Proxy Python Rancher Rant Redis Roundcube SSL Samba Seafile Security Shell SmartOS Solaris Surveillance Systemd TLS Tomcat Ubuntu Unix VMware Varnish Virtualization Windows Wireless Wordpress Wyse ZFS Znuny Zoneminder