
For a particular application deployed in a Kubernetes cluster, we needed to deploy Varnish in front of the application. Varnish should be used to serve cached content to both the outside world but also to other applications, running in the same K8s cluster.
The mission sounds easy. But there were a couple of hurdles to jump!
The official Varnish container image (we used the LTS version varnish:6.0) is very quickly deployed. However there is one major caveat, nobody warns you on the official Varnish Docker documentation: Varnish does not support a backend server which resolves to multiple IP addresses!
In the Varnish example, a single container is used as backend, resolving simply to "httpd" (the deployment or container name), but when you're in a Kubernetes cluster, you (most likely) run multiple pods of your application.
The following backend configuration in Varnish's VCL works fine with a single pod:
$ cat vcl/app.vcl
vcl 4.0;
import std;
backend app {
.host = "app";
.port = "3005";
.probe = {
.request =
"GET /_health HTTP/1.1"
"Host: app.example.com"
"Connection: close";
.interval = 2s;
.timeout = 5s;
.window = 5;
.threshold = 2;
}
}
[...]
However if "app" was deployed as DaemonSet (one pod per node) or as a deployment with scale > 1, then Varnish will fail to start, blaming too many IP addresses resolving to "app":
Error:
Message from VCC-compiler:
Backend host "app": resolves to too many addresses.
Only one IPv4 and one IPv6 are allowed.
Please specify which exact address you want to use, we found all of these:
10.42.1.229:3005
10.42.1.234:3005
10.42.2.197:3005
('/etc/varnish/varnish.vcl' Line 6 Pos 13)
.host = "app";
------------#######-
In backend specification starting at:
('/etc/varnish/varnish.vcl' Line 5 Pos 1)
backend app {
#######--------
Running VCC-compiler failed, exited with 2
VCL compilation failed
A potential fix would be to create a backend for each pod, but the pod's ip addresses can change pretty quickly and the pods may scale down and up.
Note: In the past this could have been solved using Varnish 3.x and the director VMOD. There is an excellent article from Dridi Boukelmoune about this topic. Unfortunately this solution doesn't work in today's Varnish and the presented successor (the vmod_goto) is only part of the Varnish Plus (commercial) variant.
To handle multiple pods behind this single Varnish backend, we decided to install a HAProxy in between Varnish and the "app" application.
Now is probably a good time to show what the proposed architecture actually looks like:
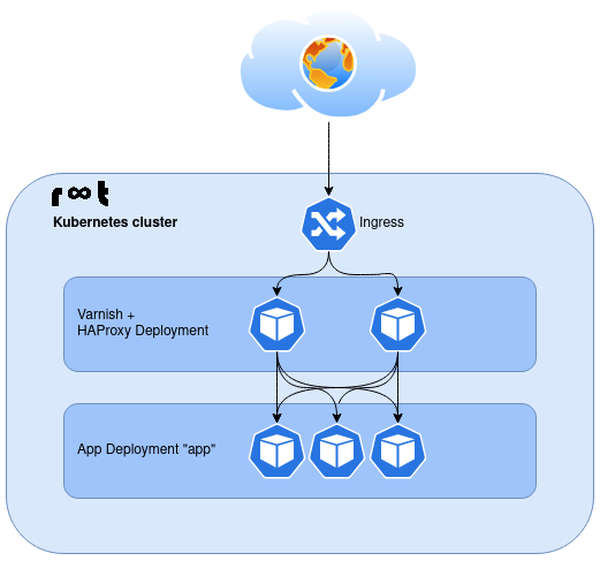
The drawing shows the traffic coming in, through the Kubernetes Ingress, and is then balanced across the Varnish deployment. From the Varnish pods, the backend application "app" is then accessed, again using Kubernetes' internal load balancing (round robin).
As mentioned before, we decided to use HAProxy alongside Varnish. First we thought about yet another deployment "haproxy", but we would have run into the same problem again with multiple IP addresses resolving to the backend "haproxy" - Varnish would fail again. To solve this, we modified the Varnish image and installed HAProxy.
This might sound weird, but it's an actual fact. When installing HAProxy inside a container using a package repository, HAProxy will not start inside a Docker container. The Varnish image is based on a Debian 11 (Bullseye) image and this tries to install HAProxy from the APT repositories. The problem here is that both Debian's and Ubuntu's HAProxy package maintainers have trimmed the package to be installed with a distribution running Systemd as init system. But Docker does not support Systemd as init system. With a couple of workarounds this problem can be solved, too. We have described this in a past article: HAProxy in Ubuntu 18.04 Docker image not starting: cannot bind UNIX socket.
Docker containers are supposed to be micro-deployments, running one process/application per container. A container is supposed to start a single process and keep it running in the foreground. The process dies means the container dies with it. But in our case we need to start Varnish and HAProxy in the same container. To achieve this, we switched to supervisord - a kind of "init system as an application". Supervisord makes sure all commands in the configuration are started:
$ cat supervisor/supervisord.conf
[supervisord]
nodaemon=true
[program:varnish]
command=/usr/sbin/varnishd -j unix,user=vcache -a :6081 -T localhost:6082 -f /etc/varnish/varnish.vcl -s malloc,128m
priority=100
[program:haproxy]
command=/usr/sbin/haproxy -W -f /etc/haproxy/haproxy.cfg
Note: This is the config seen in the code repository. The config file will then be copied to /etc/supervisor/conf.d/supervisord.conf - this is done in the Dockerfile.
Once the new image was built and deployed, HAProxy was strangely running with two processes (running alongside, not child process). Even the listener (port 8080) showed up twice. This turned out to be an error in the HAProxy config (/etc/haproxy/haproxy.cfg). We used an existing haproxy.cfg from a standard HAProxy installation and this contained the "daemon" parameter in the global section:
root@focal:~# cat /etc/haproxy/haproxy.cfg
global
log /dev/log local0
log /dev/log local1 notice
chroot /var/lib/haproxy
stats socket /run/haproxy/admin.sock mode 660 level admin expose-fd listeners
stats timeout 30s
user haproxy
group haproxy
daemon
[...]
When HAProxy is started by supervisord, you want to make sure you remove the "daemon" parameter.
HAProxy is unable to log into a file. The only possibilities are to log into a socket or to a syslog server. To create a local logging, a socket needs to be created. This can be done by using rsyslog and the following config:
$ cat haproxy/syslog.conf
# Create an additional socket in haproxy's chroot in order to allow logging via
# /dev/log to chroot'ed HAProxy processes
$AddUnixListenSocket /var/lib/haproxy/dev/log
# Send HAProxy messages to a dedicated logfile
if $programname startswith 'haproxy' then /var/log/haproxy.log
&~
In the Dockerfile, this config will be placed into the final path /etc/rsyslog.d/49-haproxy.conf.
To be able to catch the HAProxy logs in the container's stdout, a symbolic link can be created in the Dockerfile:
# forward logs to docker log collector
RUN ln -sf /proc/1/fd/1 /var/log/haproxy.log
When this container is started, rsyslogd needs to be started, too. Another couple of lines in supervisord.conf and this is solved:
$ cat supervisor/supervisord.conf
[supervisord]
nodaemon=true
[program:rsyslog]
command=/usr/sbin/rsyslogd
[program:varnish]
command=/usr/sbin/varnishd -j unix,user=vcache -a :6081 -T localhost:6082 -f /etc/varnish/varnish.vcl -s malloc,128m
priority=100
[program:haproxy]
command=/usr/sbin/haproxy -W -f /etc/haproxy/haproxy.cfg
The weirdest problem of all was faced when the Varnish-HAProxy deployment was started. Varnish, HAProxy and rsyslog started correctly and the HAProxy logs could be followed in the container's stdout logging. The first couple of seconds it looked as if everything was working as it should:
Dec 16 20:07:59 app-varnish-zq4fh haproxy[20]: 127.0.0.1:39568 [16/Dec/2021:20:07:59.964] app app/app 0/0/0/2/2 200 413 - - ---- 1/1/0/0/0 0/0 "GET /_health HTTP/1.1"
Dec 16 20:08:01 app-varnish-zq4fh haproxy[20]: 127.0.0.1:39708 [16/Dec/2021:20:08:01.973] app app/app 0/0/2/2/4 200 413 - - ---- 1/1/0/0/0 0/0 "GET /_health HTTP/1.1"
Dec 16 20:08:03 app-varnish-zq4fh haproxy[20]: 127.0.0.1:39834 [16/Dec/2021:20:08:03.978] app app/app 0/0/0/2/2 200 413 - - ---- 1/1/0/0/0 0/0 "GET /_health HTTP/1.1"
Dec 16 20:08:05 app-varnish-zq4fh haproxy[20]: 127.0.0.1:39992 [16/Dec/2021:20:08:05.981] app app/app 0/0/0/2/2 200 413 - - ---- 2/2/0/0/0 0/0 "GET /_health HTTP/1.1"
Dec 16 20:08:07 app-varnish-zq4fh haproxy[20]: 127.0.0.1:40136 [16/Dec/2021:20:08:07.983] app app/app 0/0/0/1/1 200 413 - - ---- 2/2/0/0/0 0/0 "GET /_health HTTP/1.1"
Dec 16 20:08:09 app-varnish-zq4fh haproxy[20]: 127.0.0.1:40276 [16/Dec/2021:20:08:09.986] app app/app 0/0/0/3/3 200 413 - - ---- 2/2/0/0/0 0/0 "GET /_health HTTP/1.1"
Dec 16 20:08:11 app-varnish-zq4fh haproxy[20]: 127.0.0.1:40428 [16/Dec/2021:20:08:11.990] app app/app 0/0/0/2/2 200 413 - - ---- 2/2/0/0/0 0/0 "GET /_health HTTP/1.1"
Dec 16 20:08:13 app-varnish-zq4fh haproxy[20]: 127.0.0.1:40578 [16/Dec/2021:20:08:13.992] app app/app 0/0/0/1/1 200 413 - - ---- 2/2/0/0/0 0/0 "GET /_health HTTP/1.1"
Dec 16 20:08:15 app-varnish-zq4fh haproxy[20]: 127.0.0.1:40720 [16/Dec/2021:20:08:15.995] app app/app 0/0/1/1/2 200 413 - - ---- 2/2/0/0/0 0/0 "GET /_health HTTP/1.1"
Dec 16 20:08:18 app-varnish-zq4fh haproxy[20]: 127.0.0.1:40972 [16/Dec/2021:20:08:17.998] app app/app 0/0/0/2/2 200 413 - - ---- 2/2/0/0/0 0/0 "GET /_health HTTP/1.1"
Dec 16 20:08:20 app-varnish-zq4fh haproxy[20]: 127.0.0.1:41150 [16/Dec/2021:20:08:20.001] app app/app 0/0/0/2/2 200 413 - - ---- 2/2/0/0/0 0/0 "GET /_health HTTP/1.1"
Dec 16 20:08:22 app-varnish-zq4fh haproxy[20]: 127.0.0.1:41298 [16/Dec/2021:20:08:22.003] app app/app 0/0/0/2/2 200 413 - - ---- 2/2/0/0/0 0/0 "GET /_health HTTP/1.1"
Dec 16 20:08:24 app-varnish-zq4fh haproxy[20]: 127.0.0.1:41424 [16/Dec/2021:20:08:24.006] app app/app 0/0/0/1/1 200 413 - - ---- 2/2/0/0/0 0/0 "GET /_health HTTP/1.1"
Dec 16 20:08:26 app-varnish-zq4fh haproxy[20]: 127.0.0.1:41548 [16/Dec/2021:20:08:26.008] app app/app 0/0/0/2/2 200 413 - - ---- 2/2/0/0/0 0/0 "GET /_health HTTP/1.1"
Dec 16 20:08:28 app-varnish-zq4fh haproxy[20]: 127.0.0.1:41694 [16/Dec/2021:20:08:28.010] app app/app 0/0/0/4/4 200 413 - - ---- 2/2/0/0/0 0/0 "GET /_health HTTP/1.1"
Dec 16 20:08:29 app-varnish-zq4fh haproxy[20]: Server app/app is going DOWN for maintenance (DNS NX status). 0 active and 0 backup servers left. 0 sessions active, 0 requeued, 0 remaining in queue.
Dec 16 20:08:29 app-varnish-zq4fh haproxy[20]: Server app/app is going DOWN for maintenance (DNS NX status). 0 active and 0 backup servers left. 0 sessions active, 0 requeued, 0 remaining in queue.
Dec 16 20:08:29 app-varnish-zq4fh haproxy[20]: backend app has no server available!
Dec 16 20:08:29 app-varnish-zq4fh haproxy[20]: backend app has no server available!
Dec 16 20:08:30 app-varnish-zq4fh haproxy[20]: 127.0.0.1:41834 [16/Dec/2021:20:08:30.015] app app/<NOSRV> 0/-1/-1/-1/0 503 221 - - SC-- 2/2/0/0/0 0/0 "GET /_health HTTP/1.1"
Dec 16 20:08:32 app-varnish-zq4fh haproxy[20]: 127.0.0.1:41952 [16/Dec/2021:20:08:32.015] app app/<NOSRV> 0/-1/-1/-1/0 503 221 - - SC-- 2/2/0/0/0 0/0 "GET /_health HTTP/1.1"
Dec 16 20:08:34 app-varnish-zq4fh haproxy[20]: 127.0.0.1:42086 [16/Dec/2021:20:08:34.016] app app/<NOSRV> 0/-1/-1/-1/0 503 221 - - SC-- 2/2/0/0/0 0/0 "GET /_health HTTP/1.1"
Dec 16 20:08:36 app-varnish-zq4fh haproxy[20]: 127.0.0.1:42702 [16/Dec/2021:20:08:36.016] app app/<NOSRV> 0/-1/-1/-1/0 503 221 - - SC-- 2/2/0/0/0 0/0 "GET /_health HTTP/1.1"
Dec 16 20:08:38 app-varnish-zq4fh haproxy[20]: 127.0.0.1:42828 [16/Dec/2021:20:08:38.017] app app/<NOSRV> 0/-1/-1/-1/0 503 221 - - SC-- 2/2/0/0/0 0/0 "GET /_health HTTP/1.1"
[...]
But all of a sudden, the backend server "app" went down - with a NS NX status as reason. From this moment on, the backend server never recovered and remained down.
A closer look at the HAProxy config showed no issues:
root@app-varnish-zq4fh:/etc/varnish# tail -n 15 /etc/haproxy/haproxy.cfg
resolvers mydns
accepted_payload_size 8192
parse-resolv-conf
hold valid 10s
### FRONTEND ###
frontend app
bind 0.0.0.0:8080
default_backend app
### BACKEND ###
backend app
option httpchk GET /_health HTTP/1.1\r\nHost:\ monitoring\r\nConnection:\ close
server app app:3005 id 1 maxconn 2000 check resolvers mydns inter 2s resolve-prefer ipv4
Note: The resolvers section is needed in a HAProxy installation, where DNS changes of the backends are likely to occur. Without the resolvers, HAProxy resolves the backend only once at startup.
With additional programs installed (net-tools) in the container, this behaviour could indeed be reproduced. Inside the container, the backend's DNS name "app" could not be resolved anymore:
root@app-varnish-zq4fh:/etc/varnish# dig -t A app @10.43.0.10
; <<>> DiG 9.16.22-Debian <<>> -t A app @10.43.0.10
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 52730
;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 4096
; COOKIE: 047fb96b3a3bbca9 (echoed)
;; QUESTION SECTION:
;app. IN A
;; Query time: 4 msec
;; SERVER: 10.43.0.10#53(10.43.0.10)
;; WHEN: Thu Dec 16 20:19:26 UTC 2021
;; MSG SIZE rcvd: 46
However tcpdump (still in the container) clearly showed, that HAProxy tried to resolve the backend name continuously:
root@app-varnish-zq4fh:/etc/varnish# tcpdump -nn host 10.42.2.191 and port 53
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), snapshot length 262144 bytes
20:18:10.015529 IP 10.42.2.191.57034 > 10.43.0.10.53: 61654+ [1au] A? app. (34)
20:18:10.016517 IP 10.43.0.10.53 > 10.42.2.191.57034: 61654 NXDomain 0/0/1 (34)
20:18:10.016557 IP 10.42.2.191.57034 > 10.43.0.10.53: 61654+ [1au] AAAA? app. (34)
20:18:10.017303 IP 10.43.0.10.53 > 10.42.2.191.57034: 61654 NXDomain 0/0/1 (34)
20:18:11.017657 IP 10.42.2.191.57034 > 10.43.0.10.53: 47362+ [1au] A? app. (34)
20:18:11.018681 IP 10.43.0.10.53 > 10.42.2.191.57034: 47362 NXDomain 0/0/1 (34)
20:18:11.018709 IP 10.42.2.191.57034 > 10.43.0.10.53: 47362+ [1au] AAAA? app. (34)
20:18:11.019518 IP 10.43.0.10.53 > 10.42.2.191.57034: 47362 NXDomain 0/0/1 (34)
20:18:12.019288 IP 10.42.2.191.57034 > 10.43.0.10.53: 47362+ [1au] A? app. (34)
20:18:12.020331 IP 10.43.0.10.53 > 10.42.2.191.57034: 47362 NXDomain 0/0/1 (34)
20:18:12.020377 IP 10.42.2.191.57034 > 10.43.0.10.53: 47362+ [1au] AAAA? app. (34)
20:18:12.021226 IP 10.43.0.10.53 > 10.42.2.191.57034: 47362 NXDomain 0/0/1 (34)
20:18:13.020853 IP 10.42.2.191.57034 > 10.43.0.10.53: 47362+ [1au] A? app. (34)
20:18:13.021899 IP 10.43.0.10.53 > 10.42.2.191.57034: 47362 NXDomain 0/0/1 (34)
20:18:13.021986 IP 10.42.2.191.57034 > 10.43.0.10.53: 47362+ [1au] AAAA? app. (34)
20:18:13.022885 IP 10.43.0.10.53 > 10.42.2.191.57034: 47362 NXDomain 0/0/1 (34)
^C
16 packets captured
16 packets received by filter
0 packets dropped by kernel
But the DNS answer was always NXDomain - therefore matching the output of the HAProxy log.
As both app-varnish and app deployments are deployed in the same Kubernetes namespace, it is usually enough to use the "DNS shortname" to be able to talk to each other. But maybe that's exactly the issue here. We decided to switch and try the very same config with the Kubernetes-internal FQDN instead. And this one could be resolved without any problem:
root@app-varnish-zq4fh:/etc/varnish# dig -t A app.app.svc.cluster.local @10.43.0.10
; <<>> DiG 9.16.22-Debian <<>> -t A app.app.svc.cluster.local @10.43.0.10
;; global options: +cmd
;; Got answer:
;; WARNING: .local is reserved for Multicast DNS
;; You are currently testing what happens when an mDNS query is leaked to DNS
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 31128
;; flags: qr aa rd; QUERY: 1, ANSWER: 3, AUTHORITY: 0, ADDITIONAL: 1
;; WARNING: recursion requested but not available
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 4096
; COOKIE: 18ed7b0d223d1024 (echoed)
;; QUESTION SECTION:
;app.app.svc.cluster.local. IN A
;; ANSWER SECTION:
app.app.svc.cluster.local. 5 IN A 10.42.1.234
app.app.svc.cluster.local. 5 IN A 10.42.2.197
app.app.svc.cluster.local. 5 IN A 10.42.1.229
;; Query time: 4 msec
;; SERVER: 10.43.0.10#53(10.43.0.10)
;; WHEN: Thu Dec 16 20:20:13 UTC 2021
;; MSG SIZE rcvd: 205
After we changed the HAProxy backend (which uses an environment variable at the container start) from short to full internal DNS name, the containers were restarted.
Right after the container start, we verified the HAProxy logs:
Dec 16 20:22:27 app-varnish-fdbk5 haproxy[21]: 127.0.0.1:51196 [16/Dec/2021:20:22:27.490] app app/app.app.svc.cluster.local 0/0/0/2/2 200 413 - - ---- 1/1/0/0/0 0/0 "GET /_health HTTP/1.1"
Dec 16 20:22:29 app-varnish-fdbk5 haproxy[21]: 127.0.0.1:51342 [16/Dec/2021:20:22:29.492] app app/app.app.svc.cluster.local 0/0/0/1/1 200 413 - - ---- 1/1/0/0/0 0/0 "GET /_health HTTP/1.1"
[...]
Dec 16 20:23:47 app-varnish-fdbk5 haproxy[21]: 127.0.0.1:57402 [16/Dec/2021:20:23:47.781] app app/app.app.svc.cluster.local 0/0/0/4/4 200 413 - - ---- 2/2/0/0/0 0/0 "GET /_health HTTP/1.1"
Dec 16 20:23:49 app-varnish-fdbk5 haproxy[21]: 127.0.0.1:57564 [16/Dec/2021:20:23:49.786] app app/app.app.svc.cluster.local 0/0/0/1/1 200 413 - - ---- 2/2/0/0/0 0/0 "GET /_health HTTP/1.1"
Even after more than a minute, the HAProxy backend is still up. What a change compared to the DNS short name!
Many paths lead to Rome.
That quote is true, in particular when working with Kubernetes clusters. Another idea we were thinking about, was to use HAProxy as a side-car container (inside the Varnish pod). This way Varnish could still talk with HAProxy using "localhost" - yet the processes would run in separate containers. Maybe we will try this possibility in the future.
Although currently called "the de-facto container infrastructure",
Kubernetes is anything but easy. The complexity adds additional problems
and considerations. At Infiniroot we love to share our troubleshooting
knowledge when we need to tackle certain issues - but we also know this
is not for everyone ("it just needs to work"). So if you are looking for
a managed and dedicated Kubernetes environment, managed by Rancher 2, with server location Switzerland, check out our Private Kubernetes Container Cloud Infrastructure service at Infiniroot.
No comments yet.

AI AWS Android Ansible Apache Apple Atlassian BSD Backup Bash Bluecoat CMS Chef Cloud Coding Consul Containers CouchDB DB DNS Databases Docker ELK Elasticsearch Filebeat FreeBSD Galera Git GlusterFS Grafana Graphics HAProxy HTML Hacks Hardware Icinga Influx Internet Java KVM Kibana Kodi Kubernetes LVM LXC Linux Logstash Mac Macintosh Mail MariaDB Minio MongoDB Monitoring Multimedia MySQL NFS Nagios Network Nginx OSSEC OTRS Observability Office OpenSearch PHP Perl Personal PostgreSQL PowerDNS Proxmox Proxy Python Rancher Rant Redis Roundcube SSL Samba Seafile Security Shell SmartOS Solaris Surveillance Systemd TLS Tomcat Ubuntu Unix VMware Varnish Virtualization Windows Wireless Wordpress Wyse ZFS Znuny Zoneminder