
When running mysqldump to create a backup from a MySQL, Percona or MariaDB database, the default output is a non-compressed data dump of the database. This output is then usually saved into a file with extension .sql to quickly identify what this file is about.
But of course the larger the databases are, each dump eats up more disk space. This is where compression comes in; the data is compressed by using a certain algorithm. Windows users mostly know the zip compression method (from the .zip files), but there are many others - especially on Linux.
However finding the right compression method isn't always easy. Certain methods can be very slow but offer a great compression resulting in a smaller dump file, others are faster but the resulting file is larger. This is where this blog article should help you.
Note: Yes, there are alternatives to mysqldump (such as mydumper) but here we focus on the compression comparison.
The goal of this mysqldump compression comparison is to run a benchmark test using different compression methods and find the best* one.
*best: Fast but still with a good compressed dump size.
The tests were run on the same machine, a virtual machine with 4 vCPU and 8 GB memory running Ubuntu 18.04. Database engine is MariaDB 10.3. The database size is roughly 42 GB, according to the SQL query to measure database size. The MariaDB server is part of a Galera cluster in a test environment with some but not too many IOPS.
Although this test system doesn't use the latest versions (neither OS nor MariaDB), the comparison results still show clear advantages (or disadvantages) of each compression method.
For each test run, the mysqldump output is read from stdout, piped to the compression command (such as gzip) and written into a single file:
$ time mysqldump --routines --events --single-transaction --quick database | compression > /backup/database.sql.suffix
Only taking a backup using mysqldump was considered in this comparison tests. Restore tests (decompression comparison) were not made.
The following table represents the results of mysqldump using different compression methods. Best results are marked bold.
| Compression | Dump result |
Dump size (Bytes) |
Dump duration (s) |
Max load (5m) |
| gzip | OK | 1946688843 | 833 |
1.92 |
| xz | FAIL (Error 1412 during very slow processing) |
- | - | - |
| xz -T0 |
OK | 1373860176 | 1819 |
5.35 |
| bzip2 | OK | 1520139497 | 2761 |
1.65 |
| zstd | OK | 1912134240 | 692 |
1.59 |
| zip | OK | 1948097645 | 733 | 1.90 |
| lz4 | OK | 3222237040 | 730 | 1.69 |
| 7z | OK | 1394298203 | 2401 | 3.65 |
| pigz | OK | 1949663895 | 781 | 2.63 |
| lzop | OK | 3456824011 | 701 | 1.83 |
| lzma |
OK |
1323076911 |
10520 |
1.53 |
Taking a data dump with the xz compression (without additional parameters) resulted in an error (MySQL Error 1412) during the mysqldump process. This was after roughly 4000s running the dump already.
The following graph shows a visual comparison of the different sizes of the final compressed dump file. Obviously a lower file size is better.
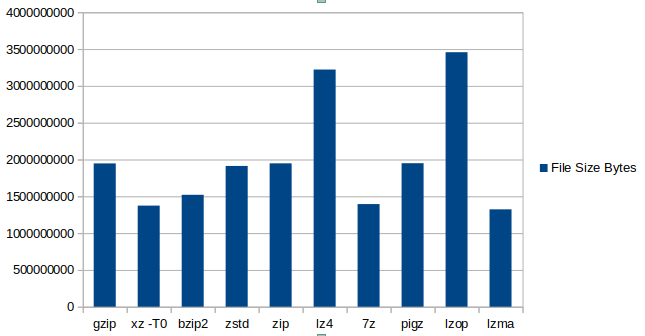
According to this chart, lzma is the winner. Remember, the original database size is ~42 GB.
The following graph shows a visual comparison of the processing speed; how long (in seconds) did it take the mysqldump process (with compression) until the final dump file was finished. A lower backup duration is better.
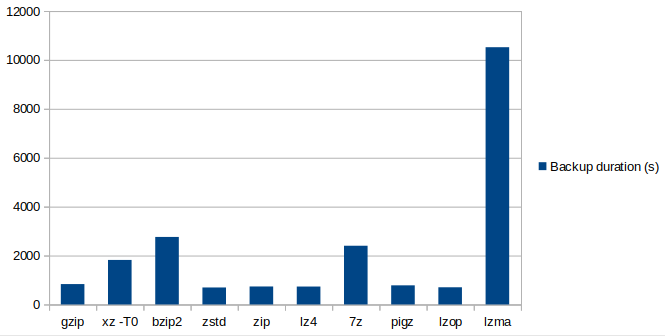
lzma is the slowest compression method, by far. The winner here is zstd, closely followed by lzop, lz4, zip and pigz.
Another important value to look at is the CPU load during the backup process. A fast backup or a small dump file doesn't help a lot when the machine itself gets very slow due to high load. For this purpose the highest 5min load value during the mysqldump process was noted. A lower load value is better.
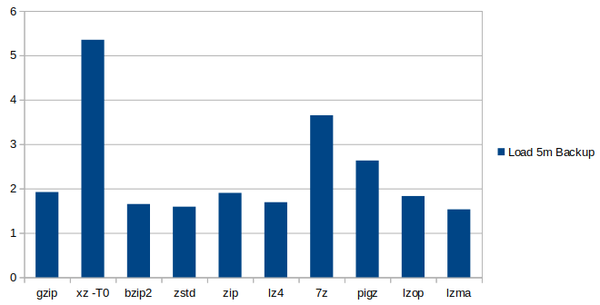
The winner in this chart is quite a surprise: Although zstd finished first in the speed chart above, it also used the least CPU resources and caused the lowest increase in CPU load (5m). xz and 7z on the other hand used a lot of CPU resources with a load above 5 and 3 (remember, this VM has 4 CPUs).
The comparison results show a winner: zstd. This lesser known compression method beat all the others, especially in terms of performance (speed). The compressed file size was in line with other (but slower) compression methods.
Major differences can often be spotted where the compression of the mysqldump output happens on multiple threads. Not all compression commands use multi-threading and can therefore be slower.
At Infiniroot, we've been using the gzip compression method for all database backup processes. The results show that there are better performing compression methods, but it looks like we didn't bet on the slowest horse here. For large databases (starting from 100 GB) a switch from gzip to zstd could make sense and help reduce the daily backup duration.
No comments yet.

AI AWS Android Ansible Apache Apple Atlassian BSD Backup Bash Bluecoat CMS Chef Cloud Coding Consul Containers CouchDB DB DNS Databases Docker ELK Elasticsearch Filebeat FreeBSD Galera Git GlusterFS Grafana Graphics HAProxy HTML Hacks Hardware Icinga Influx Internet Java KVM Kibana Kodi Kubernetes LVM LXC Linux Logstash Mac Macintosh Mail MariaDB Minio MongoDB Monitoring Multimedia MySQL NFS Nagios Network Nginx OSSEC OTRS Observability Office OpenSearch PHP Perl Personal PostgreSQL PowerDNS Proxmox Proxy Python Rancher Rant Redis Roundcube SSL Samba Seafile Security Shell SmartOS Solaris Surveillance Systemd TLS Tomcat Ubuntu Unix VMware Varnish Virtualization Windows Wireless Wordpress Wyse ZFS Znuny Zoneminder