
Today I was contacted by another Systems Engineer, that weird errors were detected in the NetBackup application. The errors could be seen in Reports -> Problems (in the GUI).
All of them looked the same and were triggered every 3 mins:
could not process request from pmoinfr01.local.domain
get_string() failed - premature end of file encountered (5)
Here the actual screenshot:
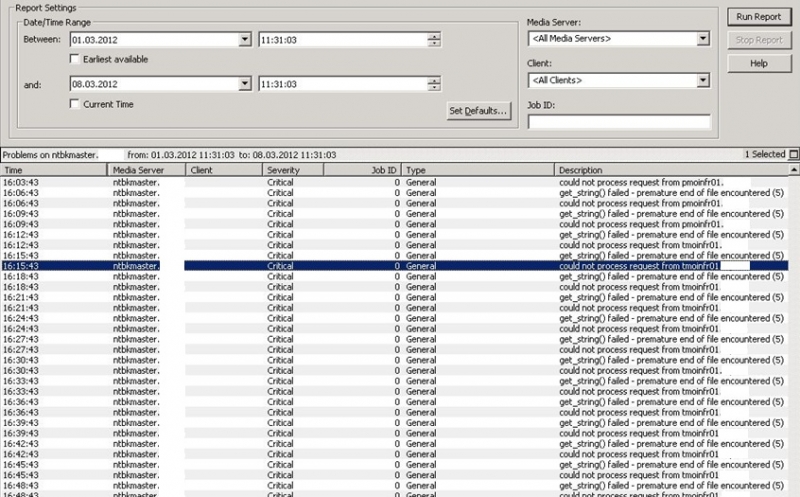
Already by the name 'pmoinfr01' I knew that my Nagios monitoring must be involved, the fact that this happens every 3 mins is another indicator (as my standard checks are launched every 3rd minute). But which check is doing this?
Besides the standard operating systems checks as CPU, Memory, Disk, etc. I also check typical NetBackup services and ports for their availability.
The important ports to check on a NetBackup Master server are: 13701, 13720, 13721, 13782. These ports are checked by check_tcp.
After some tcpdumping and manual tests, I figured out that check_tcp on port 13720 is causing these critical errors in the logs (Reports). It seems that check_tcp is submitting code to this port which can't be handled on the target side which then result in errors in the logs.
So if one receives such errors in his NetBackup application, you must deactivate the monitoring of port 13720 (at least not by check_tcp) and the spamming in your logs will stop.No comments yet.

AI AWS Android Ansible Apache Apple Atlassian BSD Backup Bash Bluecoat CMS Chef Cloud Coding Consul Containers CouchDB DB DNS Databases Docker ELK Elasticsearch Filebeat FreeBSD Galera Git GlusterFS Grafana Graphics HAProxy HTML Hacks Hardware Icinga Influx Internet Java KVM Kibana Kodi Kubernetes LVM LXC Linux Logstash Mac Macintosh Mail MariaDB Minio MongoDB Monitoring Multimedia MySQL NFS Nagios Network Nginx OSSEC OTRS Observability Office OpenSearch PHP Perl Personal PostgreSQL PowerDNS Proxmox Proxy Python Rancher Rant Redis Roundcube SSL Samba Seafile Security Shell SmartOS Solaris Surveillance Systemd TLS Tomcat Ubuntu Unix VMware Varnish Virtualization Windows Wireless Wordpress Wyse ZFS Znuny Zoneminder