
In February I took over an open support case about a failed restore job in NetBackup (7.1.0.2).
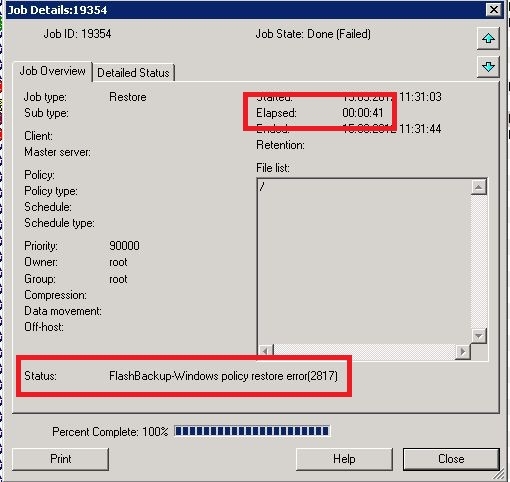
A restore of a virtual machine (without NetBackup agent installed) and with a size of around 550GB always failed after around 4.5 hours with the following error code:
Job State: Done (Failed)
FlashBackup-Windows policy restore error(2817)
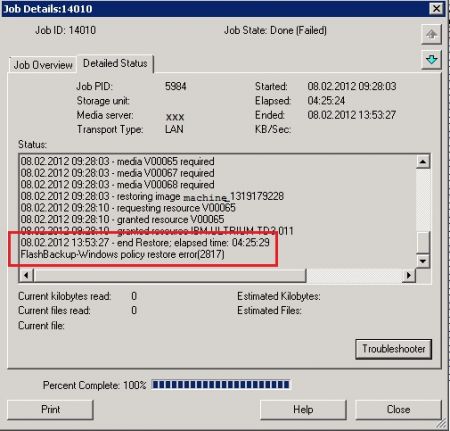
To fasten up the restore process, even though it fails, it was necessary to create a new Key called BACKUP in:
HKEY_LOCAL_MACHINE\SOFTWARE\Veritas\NetBackup\CurrentVersion\Config
In this BACKUP Key/Folder a new DWORD (32-bit) value called NoEagerlyScrub was added.
From now on the restore process still failed but right after around 40 seconds instead of more than 4 hours.
This is all done on the Media Server.
Thanks to this, the Symantec technician and I were able to make more test restores and dig into verbose log files - which had to be activated before doing a restore.
The verbose logs bpfis, tar, bpvmutil and vxms are activated by:
- Creating the folders bpfis, tar, bpvmutil in
- Changing the Logging DWORD value in HKEY_LOCAL_MACHINE\SOFTWARE\VERITAS\VxMS to 7580 (hexadecimal). The logs are created in C:\Program Files\Common Files\VERITAS\VxMS\Logs\.
As before, this is also done on the Media Server.
Then, before launching the restore itself, in the BAR (Backup Archive and Restore) Console go to File ? Netbackup Client Properties ? Troubleshooting and set Verbose to 5 and General to 2.
Don't forget to reset all this values and registry keys or your Media Server will use the full disk pretty soon!
After having launched another restore, which failed again with error 2817, the following entries were found in the log bpvmutil:
11:31:43.889 [4284.3340] restore_freeze: creating snapshot for /uuid/42008944-0345-33f2-23a3-05ff2237c97b
11:31:44.123 [4284.3340] vmwareLogger: WaitForTaskCompleteEx: reached Error!
11:31:44.123 [4284.3340] vmwareLogger: WaitForTaskCompleteEx: Another task is already in progress.
11:31:44.123 [4284.3340] vmwareLogger: WaitForTaskCompleteEx: SYM_VMC_ERROR: TASK_REACHED_ERROR_STATE
11:31:44.123 [4284.3340] vmwareLogger: CreateSnapshot(2): SYM_VMC_ERROR: TASK_REACHED_ERROR_STATE
11:31:44.123 [4284.3340] vmwareLogger: CreateSnapshot(1): SYM_VMC_ERROR: TASK_REACHED_ERROR_STATE
11:31:44.279 [4284.3340] restore_freeze: vmcCreateSnapshot failed with 36
11:31:44.279 [4284.3340] <2> createVMwareVM: Create restore snapshot failed for vcenter.local.domain with 36
People working with VMware know that such errors 'Another task is already in progress' come from the ESX/ESXi machines, so the problem must be on this particular ESX server.
After choosing an alternate location for the restore and selecting another ESX server than the original one, the restore process started fine and finished after ~2 hours 30 mins.
Unfortunately there was no process in the process list on the affected ESX server which showed a restore snapshot in progress or something similar, so there is no process to kill.
There are two solutions to successfully restore the virtual machine:
1. Restore the virtual machine to another ESX server. When you select 'Alternate Location' you can search for another ESX server - which has to be in the same Cluster as the original ESX. See screenshot below:
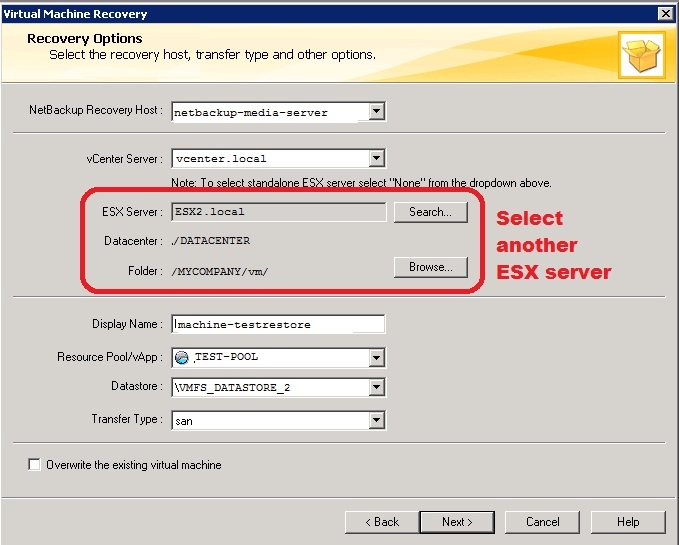
2. Restart the Management Agents on the affected ESX Server:
service mgmt-vmware restart
service vmware-vpxa restart
No comments yet.

AI AWS Android Ansible Apache Apple Atlassian BSD Backup Bash Bluecoat CMS Chef Cloud Coding Consul Containers CouchDB DB DNS Databases Docker ELK Elasticsearch Filebeat FreeBSD Galera Git GlusterFS Grafana Graphics HAProxy HTML Hacks Hardware Icinga Influx Internet Java KVM Kibana Kodi Kubernetes LVM LXC Linux Logstash Mac Macintosh Mail MariaDB Minio MongoDB Monitoring Multimedia MySQL NFS Nagios Network Nginx OSSEC OTRS Observability Office OpenSearch PHP Perl Personal PostgreSQL PowerDNS Proxmox Proxy Python Rancher Rant Redis Roundcube SSL Samba Seafile Security Shell SmartOS Solaris Surveillance Systemd TLS Tomcat Ubuntu Unix VMware Varnish Virtualization Windows Wireless Wordpress Wyse ZFS Znuny Zoneminder