
In a recent post (The Docker Dilemma: Benefits and risks going into production with Docker) I mentioned we're going forward with Rancher as an orchestration layer on top of Docker.
Since last Friday (Jan 20 2017) there were sporadic error messages shown in the user interface when new containers were about to be started:
(Expected state running but got error: Error response from daemon: oci runtime error: process_linux.go:330: running prestart hook 0 caused "fork/exec /usr/bin/dockerd (deleted): no such file or directory: ")
This got me puzzled as the file clearly exists on that particular Docker host:
root@dockerserver:~# ll /usr/bin/dockerd
-rwxr-xr-x 1 root root 39063824 Jan 13 19:44 /usr/bin/dockerd
It turned out that I ran an Ansible playbook on Friday afternoon which was written for these Rancher/Docker hosts. One of it's tasks is to ensure that the docker.io package is installed:
- name: 1.0 - Install docker.io
apt: name={{item}} state=latest
with_items:
- docker.io
The apt logs confirmed my guess:
Start-Date: 2017-01-20 15:04:06
Commandline: /usr/bin/apt-get -y -o Dpkg::Options::=--force-confdef -o Dpkg::Options::=--force-confold install docker.io
Requested-By: ansible (1001)
Upgrade: runc:amd64 (1.0.0~rc1-0ubuntu1~16.04, 1.0.0~rc1-0ubuntu2~16.04.1), docker.io:amd64 (1.12.1-0ubuntu13~16.04.1, 1.12.3-0ubuntu4~16.04.2)
End-Date: 2017-01-20 15:04:10
The docker.io package was updated from 1.12.1-0ubuntu13~16.04.1 to 1.12.3-0ubuntu4~16.04.2, but the Docker daemon was somehow not fully restarted. This is what caused the error message in Rancher, because some stale or deleted files were probably still open by the old Docker daemon process.
Syslog shows more information what exactly happened at 15:04:
Jan 20 15:04:03 dockerserver systemd[1]: Created slice User Slice of ansible.
Jan 20 15:04:03 dockerserver systemd[1]: Starting User Manager for UID 1001...
Jan 20 15:04:03 dockerserver systemd[1]: Started Session 14956 of user ansible.
Jan 20 15:04:03 dockerserver systemd[18545]: Reached target Sockets.
Jan 20 15:04:03 dockerserver systemd[18545]: Reached target Timers.
Jan 20 15:04:03 dockerserver systemd[18545]: Reached target Paths.
Jan 20 15:04:03 dockerserver systemd[18545]: Reached target Basic System.
Jan 20 15:04:03 dockerserver systemd[18545]: Reached target Default.
Jan 20 15:04:03 dockerserver systemd[18545]: Startup finished in 22ms.
Jan 20 15:04:03 dockerserver systemd[1]: Started User Manager for UID 1001.
Jan 20 15:04:08 dockerserver systemd[1]: Reloading.
Jan 20 15:04:09 dockerserver systemd[1]: apt-daily.timer: Adding 37min 2.565881s random time.
Jan 20 15:04:09 dockerserver systemd[1]: Started ACPI event daemon.
Jan 20 15:04:09 dockerserver systemd[1]: Reloading.
Jan 20 15:04:09 dockerserver systemd[1]: apt-daily.timer: Adding 5h 27min 32.130480s random time.
Jan 20 15:04:09 dockerserver systemd[1]: Started ACPI event daemon.
Jan 20 15:04:10 dockerserver systemd[1]: Reloading.
Jan 20 15:04:10 dockerserver systemd[1]: apt-daily.timer: Adding 11h 55min 14.530665s random time.
Jan 20 15:04:10 dockerserver systemd[1]: Started ACPI event daemon.
Jan 20 15:04:10 dockerserver systemd[1]: Reloading.
Jan 20 15:04:10 dockerserver systemd[1]: apt-daily.timer: Adding 11h 16min 17.514645s random time.
Jan 20 15:04:10 dockerserver systemd[1]: Started ACPI event daemon.
Jan 20 15:04:10 dockerserver systemd[1]: Started Docker Application Container Engine.
Jan 20 15:04:10 dockerserver systemd[1]: Reloading.
Jan 20 15:04:10 dockerserver systemd[1]: apt-daily.timer: Adding 11h 42min 36.963745s random time.
Jan 20 15:04:10 dockerserver systemd[1]: Started ACPI event daemon.
So we see that Docker was started (Jan 20 15:04:10 dockerserver systemd[1]: Started Docker Application Container Engine.) but where's the stop prior to that?
So to me it looks like Docker was started twice, running in two parallel processes and therefore causing sporadic error messages. A manual restart of the Docker daemon solved the problem.
If I launch a manual restart of the Docker service, this results in the following log entries:
Jan 23 09:54:38 dockerserver systemd[1]: Stopping Docker Application Container Engine...
Jan 23 09:54:50 dockerserver systemd[1]: Stopped Docker Application Container Engine.
Jan 23 09:54:50 dockerserver systemd[1]: Closed Docker Socket for the API.
Jan 23 09:54:50 dockerserver systemd[1]: Stopping Docker Socket for the API.
Jan 23 09:54:50 dockerserver systemd[1]: Starting Docker Socket for the API.
Jan 23 09:54:50 dockerserver systemd[1]: Listening on Docker Socket for the API.
Jan 23 09:54:50 dockerserver systemd[1]: Starting Docker Application Container Engine...
Jan 23 09:54:54 dockerserver dockerd[26724]: time="2017-01-23T09:54:54.088301837+01:00" level=info msg="Docker daemon" commit=6b644ec graphdriver=aufs version=1.12.3
Jan 23 09:54:54 dockerserver systemd[1]: Started Docker Application Container Engine.
The question remains, why the update process itself didn't restart the Docker service (similar to updating other packages like MySQL or Apache). If one takes a closer look at the Debian source package, docker.io.preinst doesn't exist. In other packages (for example mysql-server) this file is responsible to stop the service prior to the package update. I created an Ubuntu bug report for this problem.
Update February 28th 2017: Today I hit a similar problem but couldn't find any hints for a problem. It all started that suddenly the containers (in a Cattle environment) couldn't talk with the containers running on another Rancher host anymore. Once again an automatic security update for the docker.io package was installed, but the Docker daemon wasn't restarted. Another symptom was that the "scheduler" container (which is a Rancher infrastructure container) was stuck in "Initializing state". Once the Docker daemon was restarted, the Docker containers on host #1 were able to talk to the containers on host #2 and vice versa again.
Lesson learned: Disable unattended upgrades in Xenial.
Update February 12th 2019: Just in case you wondered about the bug I opened, Ubuntu has reacted and has since added a restart prompt when you upgrade the docker.io package:
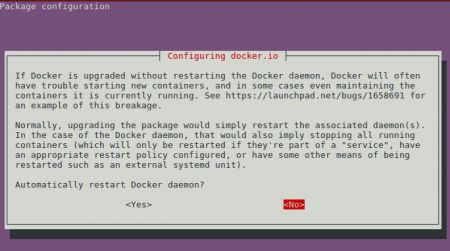
This ensures that the message is out to the server admin. Go ahead, blame me for this prompt. I'll gladly take this as a compliment ^_^v.
Michael Heiniger from Zürich wrote on Mar 29th, 2017:
Looks like Ubuntu now disabled that automatically after doing an "apt-get upgrade".
ck from Switzerland wrote on Mar 29th, 2017:
Michael, there's a file /etc/apt/apt.conf.d/20auto-upgrades. If you set the parameter's Unattended-Upgrade to the value 0, it will disable automatic upgrades:
APT::Periodic::Unattended-Upgrade "0";
Michael Heiniger from Zürich wrote on Mar 29th, 2017:
So how did you disable it?
Did you deinstall the "unattended-upgrades" packet, or did you add the package to the blacklist as shown in here: https://help.ubuntu.com/lts/serverguide/automatic-updates.html ?

AI AWS Android Ansible Apache Apple Atlassian BSD Backup Bash Bluecoat CMS Chef Cloud Coding Consul Containers CouchDB DB DNS Databases Docker ELK Elasticsearch Filebeat FreeBSD Galera Git GlusterFS Grafana Graphics HAProxy HTML Hacks Hardware Icinga Influx Internet Java KVM Kibana Kodi Kubernetes LVM LXC Linux Logstash Mac Macintosh Mail MariaDB Minio MongoDB Monitoring Multimedia MySQL NFS Nagios Network Nginx OSSEC OTRS Observability Office OpenSearch PHP Perl Personal PostgreSQL PowerDNS Proxmox Proxy Python Rancher Rant Redis Roundcube SSL Samba Seafile Security Shell SmartOS Solaris Surveillance Systemd TLS Tomcat Ubuntu Unix VMware Varnish Virtualization Windows Wireless Wordpress Wyse ZFS Znuny Zoneminder