
One of my latest tasks is a migration of Atlassian Confluence 5.7 from a pure Windows environment to a Linux environment.
Status Quo: Confluence application (Tomcat) runs on a Windows Server 2012. It's database runs on a Microsoft SQL Server 2008 R2.
Target installation: Confluence application (Tomcat) runs on an Ubuntu 16.04 machine (proably a LXC container). Database runs on a MariaDB 10.x Galera Cluster. For a test environment only a single MariaDB running localhost on the same server as the application was chosen.
But already during the first test migration I experienced a couple of issues. After one issue was solved, the next one appeared etc. The following issues were all successfully tackled.
Before migrating anything, I wanted to have a clean and empty Confluence installation. But already right after selecting the database, the (browser) setup failed with the following error message:
Hibernate operation: Could not execute query; bad SQL grammar
This turned out to be a problem with the MariaDB default settings. The default character set and collation were defined as utf8mb4 in /etc/mysql/mariadb.conf.d/50-server.cnf. If I'd have read the Atlassian documentation for Confluence Database Setup For MySQL, I'd have seen and known that this must be set to utf8 - not utf8mb4!
# MySQL/MariaDB default is Latin1, but in Debian we rather default to the full
# utf8 4-byte character set. See also client.cnf
#
# 2017-03-16 Claudio: Do not use utf8mb4 for Atlassian products!
#character-set-server = utf8mb4
#collation-server = utf8mb4_general_ci
character-set-server=utf8
collation-server=utf8_bin
There are other important MySQL settings mentioned on the Atlassian documentation. These were also applied.
After the character set and collation were adjusted and the database dropped and created from scratch, the setup ran through and it created all necessary tables.
At first I thought it would be the easiest (and fastest way) to use a dump from the MSSQL database and import it into the MariaDB/MySQL DB. But with all conversion tools I got errors. I tried it with MySQL Workbench's Migration Wizard, DBConvert for MSSQL & MySQL and HeidiSQL using database export/import. But all of them failed.
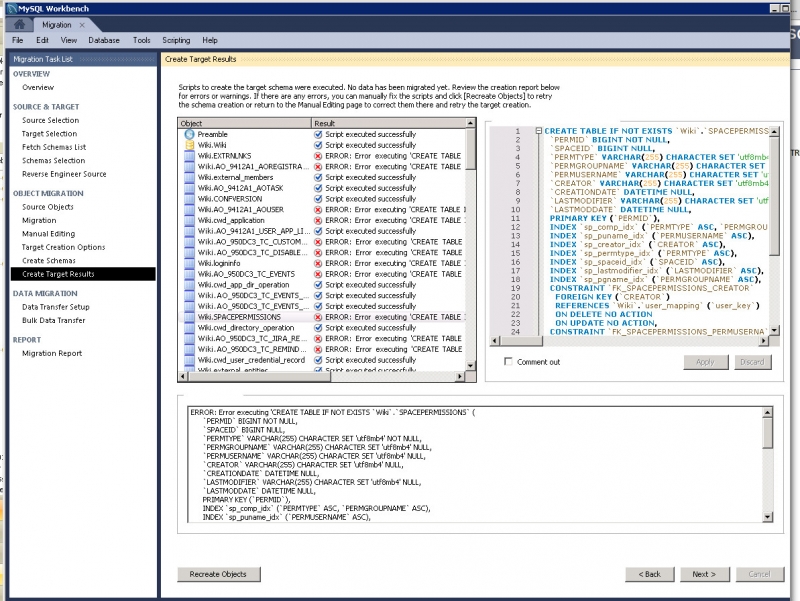
DBConvert was able to show me why:
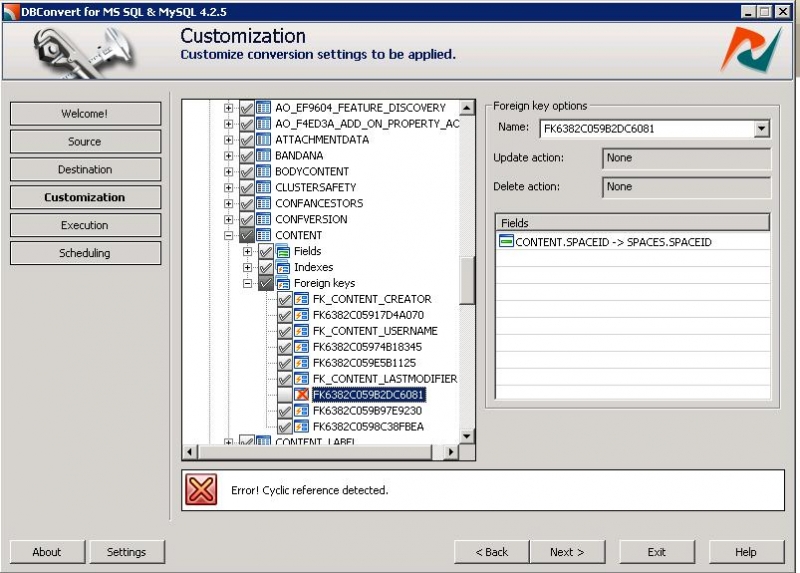
In the CONTENT table there's a foreign key pointing to the SPACES table. On the other hand in the SPACES table there's a foreign key pointing to the CONTENT table. See the dilemma? That's what's called a cycled reference, one cannot be created without the other. It results in "foreign key constraint fails" errors:
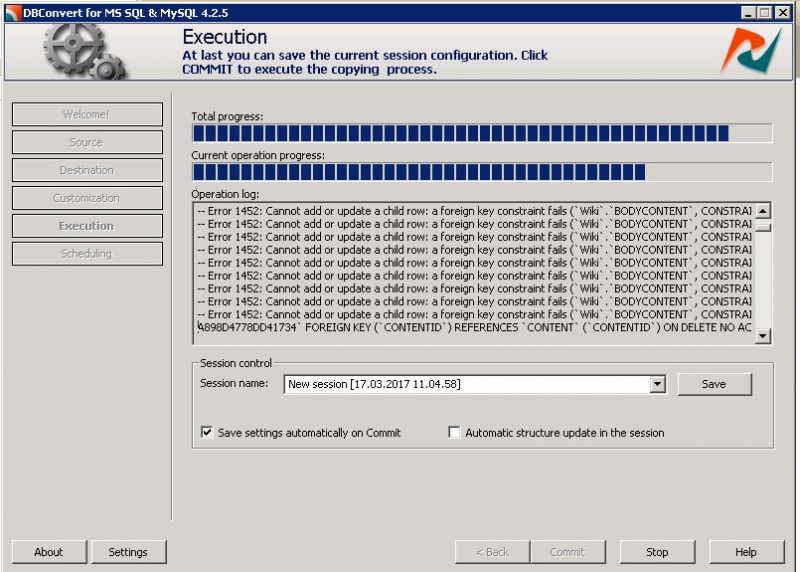
I tried to set MariaDB's GLOBAL VARIABLE to ignore the foreign key constraints (SET GLOBAL FOREIGN_KEY_CHECKS=0;) but this didn't help either.
Even with a pure data import (using data dump from a csv file) it didn't work.
At the end it turned out to be the wrong choice anyway, because the migration should be done with the Confluence backup/restore method. See below.
First considered as alternative migration process, I also tried Confluence's backup and restore method. In the old Confluence application a backup without attachments was created. This took around 30 minutes and created a zip file which contained the whole database in an xml format (entities.xml within the zip file). Once this zip file was transferred to the new Confluence server, the restore was launched from the browser (right after the database setup). But unfortunately the import failed with the following error:
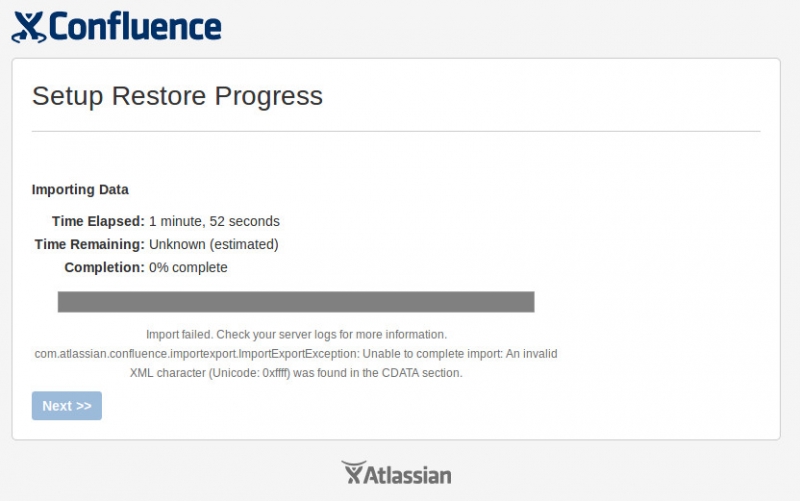
Import failed. Check your server logs for more information.
com.atlassian.confluence.importexport.ImportExportException: Unable to complete import: An invalid XML character (Unicode: 0xffff) was found in the CDATA section.
I came across some similar problems on the net and found a Perl replace command which removes this invalid character. In order to do that, the zip file must be unzipped and the command run directly on entities.xml. After this, the zip file needs to be recreated:
unzip xmlexport-20170316-145220-91.zip
perl -i -pe 's/\xef\xbf\xbf//g' entities.xml
rm xmlexport-20170316-145220-91.zip
zip xmlexport-20170316-145220-91.zip entities.xml exportDescriptor.properties plugin-data
With the newly zip file, started the restore again and this time it started importing. Until 4%...
So once the invalid XML character error was gone, the next restore failed at 4% with the following error:
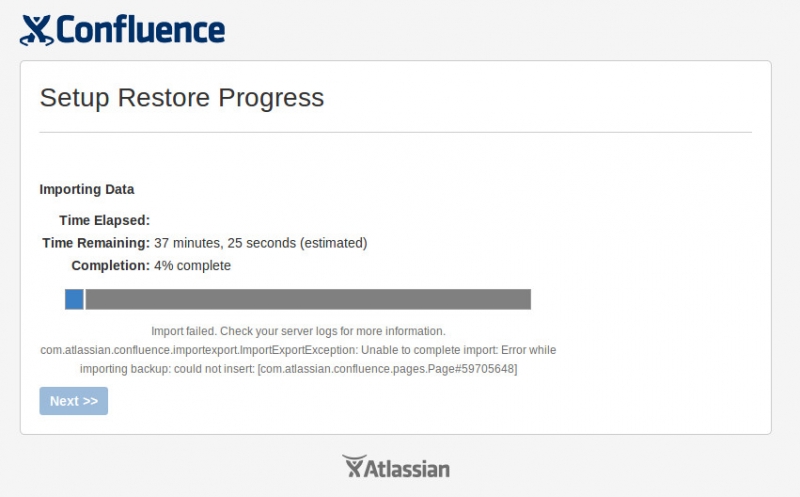
Import failed. Check your server logs for more information.
com.atlassian.foncluence.importexport.ImportExportException: Unable to complete import: Error while importing backup: could not insert: [com.atlassian.confluence.pages.Page#59705648]
This error message shown in the browser is not really helpful though. The Confluence application log ($CONFLUENCE_HOME/logs/atlassian-confluence.log) gives a better idea about the real problem:
Caused by: net.sf.hibernate.HibernateException: could not insert: [com.atlassian.confluence.pages.Page#59705648]
at net.sf.hibernate.persister.EntityPersister.insert(EntityPersister.java:475)
at net.sf.hibernate.persister.EntityPersister.insert(EntityPersister.java:436)
at net.sf.hibernate.impl.ScheduledInsertion.execute(ScheduledInsertion.java:37)
at net.sf.hibernate.impl.SessionImpl.execute(SessionImpl.java:2476)
at net.sf.hibernate.impl.SessionImpl.executeAll(SessionImpl.java:2462)
at net.sf.hibernate.impl.SessionImpl.execute(SessionImpl.java:2419)
at net.sf.hibernate.impl.SessionImpl.flush(SessionImpl.java:2288)
at com.atlassian.confluence.importexport.xmlimport.ImportProcessorContext.flushIfNeeded(ImportProcessorContext.java:246)
at com.atlassian.confluence.importexport.xmlimport.ImportProcessorContext.objectImported(ImportProcessorContext.java:81)
at com.atlassian.confluence.importexport.xmlimport.DefaultImportProcessor.persist(DefaultImportProcessor.java:50)
at com.atlassian.confluence.importexport.xmlimport.DefaultImportProcessor.processObject(DefaultImportProcessor.java:37)
at com.atlassian.confluence.importexport.xmlimport.parser.BackupParser.endElement(BackupParser.java:51)
... 44 more
Caused by: net.sf.hibernate.exception.GenericJDBCException: Could not execute JDBC batch update
at net.sf.hibernate.exception.ErrorCodeConverter.handledNonSpecificException(ErrorCodeConverter.java:90)
at net.sf.hibernate.exception.ErrorCodeConverter.convert(ErrorCodeConverter.java:79)
at net.sf.hibernate.exception.JDBCExceptionHelper.convert(JDBCExceptionHelper.java:29)
at net.sf.hibernate.impl.BatcherImpl.convert(BatcherImpl.java:328)
at net.sf.hibernate.impl.BatcherImpl.executeBatch(BatcherImpl.java:135)
at net.sf.hibernate.impl.BatcherImpl.prepareStatement(BatcherImpl.java:61)
at net.sf.hibernate.impl.BatcherImpl.prepareStatement(BatcherImpl.java:58)
at net.sf.hibernate.impl.BatcherImpl.prepareBatchStatement(BatcherImpl.java:111)
at net.sf.hibernate.persister.EntityPersister.insert(EntityPersister.java:454)
... 55 more
Caused by: java.sql.BatchUpdateException: Data truncation: Incorrect string value: '\xF0\x9F\x93\xBAF&...' for column 'BODY' at row 1
at com.mysql.jdbc.SQLError.createBatchUpdateException(SQLError.java:1167)
at com.mysql.jdbc.PreparedStatement.executeBatchSerially(PreparedStatement.java:1778)
at com.mysql.jdbc.PreparedStatement.executeBatchInternal(PreparedStatement.java:1262)
at com.mysql.jdbc.StatementImpl.executeBatch(StatementImpl.java:958)
at com.mchange.v2.c3p0.impl.NewProxyPreparedStatement.executeBatch(NewProxyPreparedStatement.java:1723)
at net.sf.hibernate.impl.BatchingBatcher.doExecuteBatch(BatchingBatcher.java:54)
at net.sf.hibernate.impl.BatcherImpl.executeBatch(BatcherImpl.java:128)
... 59 more
Caused by: com.mysql.jdbc.MysqlDataTruncation: Data truncation: Incorrect string value: '\xF0\x9F\x93\xBAF&...' for column 'BODY' at row 1
at com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:3971)
at com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:3909)
at com.mysql.jdbc.MysqlIO.sendCommand(MysqlIO.java:2527)
at com.mysql.jdbc.MysqlIO.sqlQueryDirect(MysqlIO.java:2680)
at com.mysql.jdbc.ConnectionImpl.execSQL(ConnectionImpl.java:2501)
at com.mysql.jdbc.PreparedStatement.executeInternal(PreparedStatement.java:1858)
at com.mysql.jdbc.PreparedStatement.executeUpdateInternal(PreparedStatement.java:2079)
at com.mysql.jdbc.PreparedStatement.executeBatchSerially(PreparedStatement.java:1756)
... 64 more
Again problems with some characters (incorrect string value)!
After this we contacted Atlassian's support and a few hours later we got an answer with a very helpful link: https://confluence.atlassian.com/confkb/incorrect-string-value-error-thrown-when-restoring-xml-backup-in-confluence-777009599.html
On this page, three different commands are used to fix the entities.xml file:
For the sake of completeness again the same play with the zip file and the zipped entities.xml:
# unzip backup file
unzip xmlexport-20170316-145220-91.zip
# Download Atlassian xml cleaner
wget https://confluence.atlassian.com/confkb/files/777009599/777009596/1/1439839413460/atlassian-xml-cleaner-0.1.jar
# Fix xml character issues
/opt/atlassian/confluence/jre/bin/java -jar atlassian-xml-cleaner-0.1.jar entities.xml > entities-clean.xml
perl -i -pe 's/\xef\xbf\xbf//g' entities-clean.xml
perl -i -pe 's/\xef\xbf\xbe//g' entities-clean.xml
# Recreate zip file
rm entities.xml
mv entities-clean.xml entities.xml
zip xmlexport-20170316-145220-91new.zip entities.xml exportDescriptor.properties plugin-data
Then the restore was launched again with the new created zip file xmlexport-20170316-145220-91new.zip.
The restore process was a bit over 20% complete, when my eye caught errors in the atlassian-confluence.log logfile (which I was tailing while running the restore process). The following errors appeared:
org.apache.velocity.exception.MethodInvocationException: Invocation of method 'getPrettyElapsedTime' in class com.atlassian.confluence.importexport.actions.ImportLongRunningTask threw exception java.lang.OutOfMemoryError: Java heap space at /admin/longrunningtask-xml.vm[line 5, column 19]
at org.apache.velocity.runtime.parser.node.ASTIdentifier.execute(ASTIdentifier.java:237)
at org.apache.velocity.runtime.parser.node.ASTReference.execute(ASTReference.java:262)
at org.apache.velocity.runtime.parser.node.ASTReference.render(ASTReference.java:342)
at org.apache.velocity.runtime.parser.node.SimpleNode.render(SimpleNode.java:336)
at org.apache.velocity.Template.merge(Template.java:328)
at org.apache.velocity.Template.merge(Template.java:235)
at com.opensymphony.webwork.dispatcher.VelocityResult.doExecute(VelocityResult.java:91)
[...]
Caused by: java.lang.OutOfMemoryError: Java heap space
The restore process receives a lot of data which is loaded into Tomcat's memory. The default sizing of 1GB was just too small and needed to be increased in Tomcat's setenv.sh:
grep Xmx /opt/atlassian/confluence/bin/setenv.sh
CATALINA_OPTS="$CATALINA_OPTS -Xms1024m -Xmx4096m -XX:MaxPermSize=384m -XX:+UseG1GC"
As you see I've set a new maximum heap size of 4GB.
Restarted the restore process and followed the memory usage of the Tomcat process closely. It went up to ~3500MB. Until the import was finally completed without additional errors!
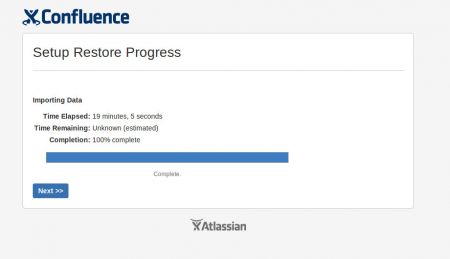
Hurray!
What all looks very easy in retrospective was a very time-consuming effort of several minds with a lot of try'n'errors. Especially the failed database migration was causing a lot of headache.
Special thanks go to Atlassian support for giving us the link we never stumbled upon (bad Google-luck I guess) and also to DBConvert which gave us some help trying to get around the foreign key constraint errors (even though we haven't bought the full software at that point)!
Need help migrating your Jira or Confluence application or looking for professional Jira or Confluence server hosting? Check out the dedicated Jira server hosting and dedicated Confluence server hosting at Infiniroot!
No comments yet.

AI AWS Android Ansible Apache Apple Atlassian BSD Backup Bash Bluecoat CMS Chef Cloud Coding Consul Containers CouchDB DB DNS Databases Docker ELK Elasticsearch Filebeat FreeBSD Galera Git GlusterFS Grafana Graphics HAProxy HTML Hacks Hardware Icinga Influx Internet Java KVM Kibana Kodi Kubernetes LVM LXC Linux Logstash Mac Macintosh Mail MariaDB Minio MongoDB Monitoring Multimedia MySQL NFS Nagios Network Nginx OSSEC OTRS Observability Office OpenSearch PHP Perl Personal PostgreSQL PowerDNS Proxmox Proxy Python Rancher Rant Redis Roundcube SSL Samba Seafile Security Shell SmartOS Solaris Surveillance Systemd TLS Tomcat Ubuntu Unix VMware Varnish Virtualization Windows Wireless Wordpress Wyse ZFS Znuny Zoneminder