
A previous article described how Rancher 2 can be upgraded to a newer release. However upgrading Rancher itself does not include a Kubernetes version upgrade - this needs to be done separately. The official documentation can be quite confusing, mentioning helm to upgrade Rancher, rke for Kubernetes and then again upgrading through the user interface. This article should help see the differences and guide through a Kubernetes upgrade.
If the whole Kubernetes upgrading process is too much hassle and you simply want to enjoy an available Kubernetes cluster to deploy your applications, check out the Private Kubernetes Cloud Infrastructure at Infiniroot!
Basically there are two types of Kubernetes clusters in a Rancher 2 environment:
Before upgrading Kubernetes, one should be careful to validate the compatibility between the different versions. Each cluster builds on top of several independent programs:
Each program requires a certain number of the other program(s). Additionally the OS needs to be checked for compatibility, too. This all results in a table like this (taken from official node requirements):

Or compatible Kubernetes versions (taken from GitHub release information):
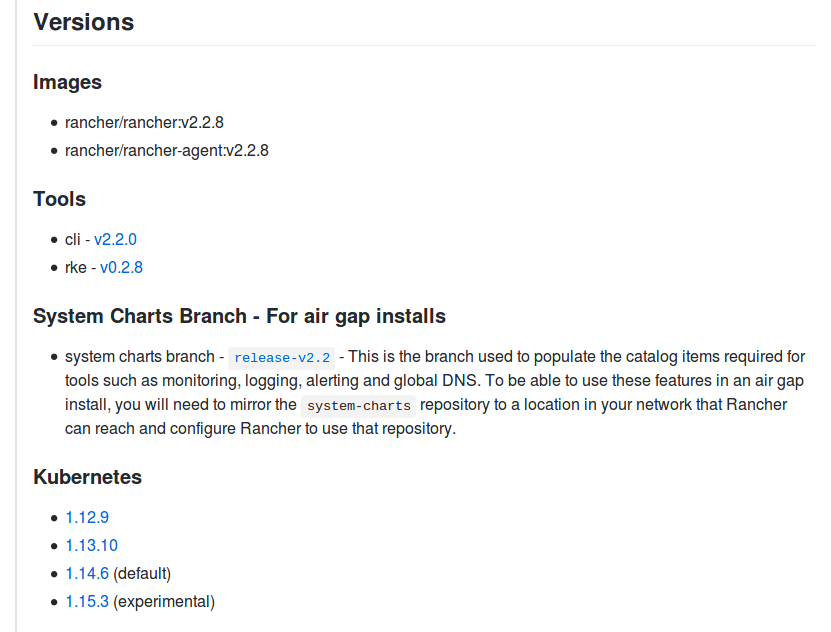
Sometimes this information must be collected from different sources.
Before upgrading Kubernetes itself, make sure Rancher itself runs with a version which will support the Kubernetes version you want to use. Click here to see how to upgrade the Rancher 2 management using helm.
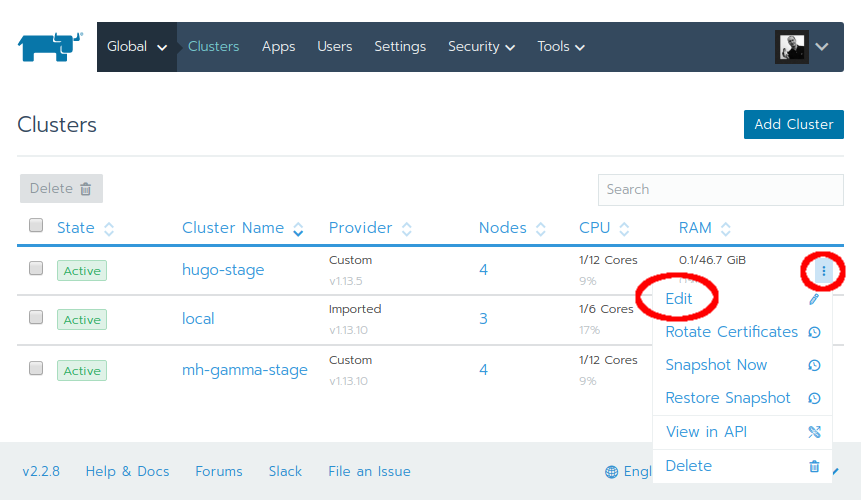
Upgrading a "child" (or "tenant") cluster, created from within Rancher management, does not involve complexity. In the Rancher UI simply click on "Clusters" in the Global view. Then click on the vertical three buttons (more) of the cluster you want to upgrade and click on Edit.
Inside the "Cluster Options" a list of compatible Kubernetes versions is available.
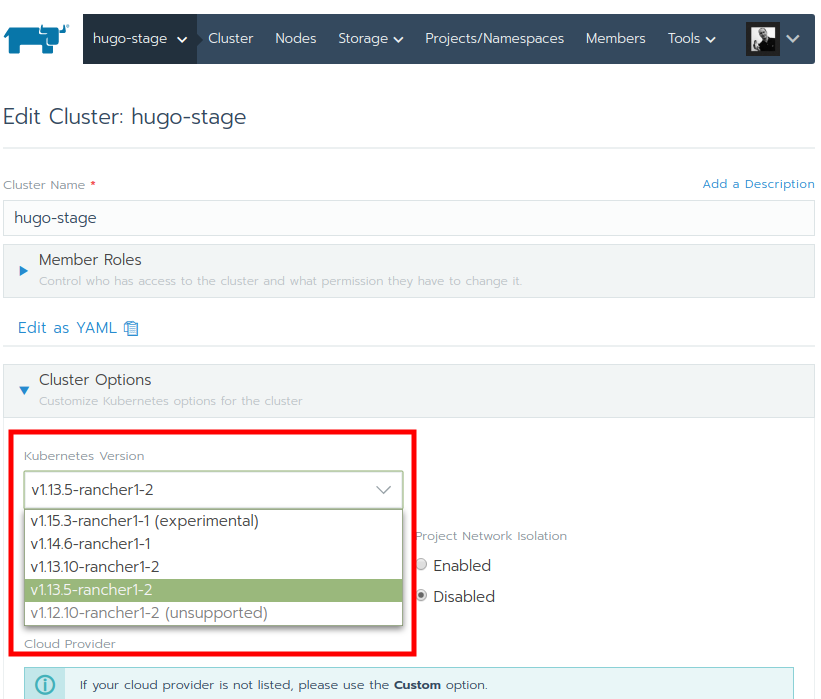
Select the Kubernetes version you want to use (upgrade) and click on Save at the bottom of the page.
The cluster will now upgrade Kubernetes on all the cluster nodes. The status can be followed on the UI. This will take a couple of minutes, until the cluster runs with the new Kubernetes version.
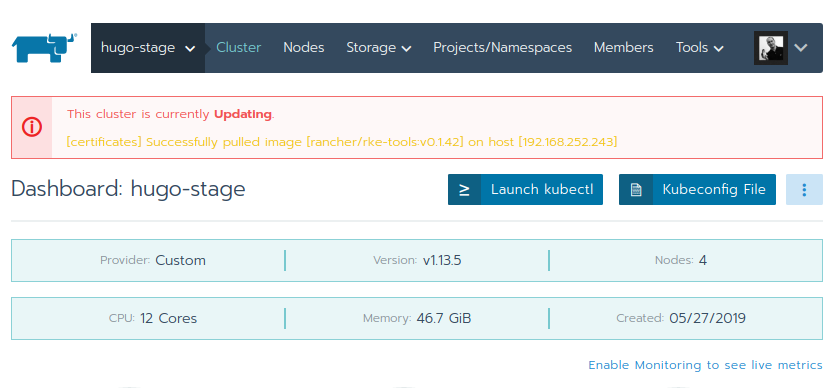
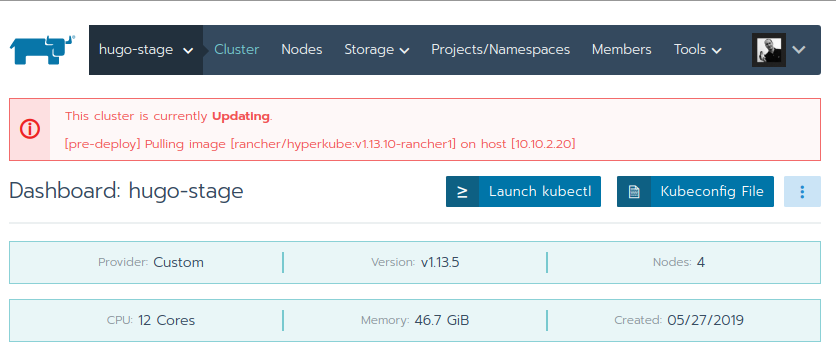
Unfortunately the "local" cluster, meaning the cluster running Rancher itself, cannot be upgraded that easy. Here the rke command needs to be used; same command which was used at the very beginning to create the Rancher 2 cluster. When the cluster was first created using rke, a yaml configuration file was used. This yaml file contains some basic information of the Rancher cluster, mainly about the nodes involved. It can grow large and complex if one wants to overwrite certain default settings, but a basic example looks like this:
$ cat 3-node-rancher-teststage.yml
nodes:
- address: 192.168.10.15
user: ansible
role: [controlplane,etcd,worker]
ssh_key_path: ~/.ssh/id_rsa
- address: 192.168.10.16
user: ansible
role: [controlplane,etcd,worker]
ssh_key_path: ~/.ssh/id_rsa
- address: 192.168.10.17
user: ansible
role: [controlplane,etcd,worker]
ssh_key_path: ~/.ssh/id_rsa
services:
etcd:
snapshot: true
creation: 6h
retention: 24h
According to the documentation, the yaml file can be adjusted to contain the wanted Kubernetes version using the rancher/hyperkube image, using the kubernetes_version value and a specific version tag:
$ cat 3-node-rancher-teststage.yml
nodes:
- address: 192.168.10.15
user: ansible
role: [controlplane,etcd,worker]
ssh_key_path: ~/.ssh/id_rsa
- address: 192.168.10.16
user: ansible
role: [controlplane,etcd,worker]
ssh_key_path: ~/.ssh/id_rsa
- address: 192.168.10.17
user: ansible
role: [controlplane,etcd,worker]
ssh_key_path: ~/.ssh/id_rsa
kubernetes_version: "v1.15.12-rancher2-2"
services:
etcd:
snapshot: true
creation: 6h
retention: 24h
The list of Rancher hyperkube releases shows which versions are available. Not all rke versions support all Kubernetes/hyperkube releases. rke itself should alert if this is the case:
$ ./rke_linux-amd64-1.1.2 up --config 3-node-rancher-test.yml
INFO[0000] Running RKE version: v1.1.2
INFO[0000] Initiating Kubernetes cluster
FATA[0000] Failed to validate cluster: v1.15.12-rancher1-2 is an unsupported Kubernetes version and system images are not populated: etcd image is not populated
However it is also possible to simply use the latest released version of rke to upgrade Kubernetes to the "current default version".
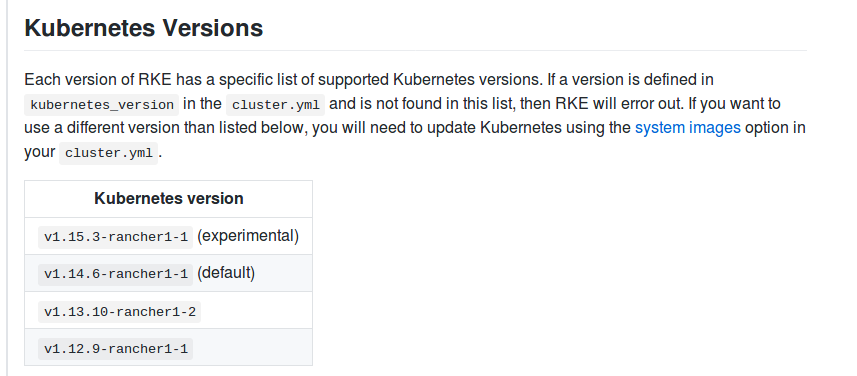
To find out which Kubernetes version is set to default on which rke version, read the rke release page.
In the following example the local cluster is upgraded from Kubernetes 1.11.3 to 1.14.6 (using the rke default) using rke 0.2.8:
$ wget https://github.com/rancher/rke/releases/download/v0.2.8/rke_linux-amd64
$ chmod 755 rke_linux-amd64; mv rke_linux-amd64{,-0.2.8}
Then rke is launched with the yaml file which was used to create the cluster:
$ ./rke_linux-amd64-0.2.8 up --config 3-node-rancher-teststage.yml
INFO[0000] Initiating Kubernetes cluster
INFO[0000] [state] Possible legacy cluster detected, trying to upgrade
INFO[0000] [reconcile] Rebuilding and updating local kube config
INFO[0000] Successfully Deployed local admin kubeconfig at [kube_config_3-node-rancher-teststage.yml]
INFO[0000] [reconcile] host [192.168.10.15] is active master on the cluster
INFO[0000] [state] Fetching cluster state from Kubernetes
INFO[0000] [state] Successfully Fetched cluster state to Kubernetes ConfigMap: cluster-state
INFO[0000] [certificates] Getting Cluster certificates from Kubernetes
INFO[0000] [certificates] Creating service account token key
INFO[0000] [certificates] Successfully fetched Cluster certificates from Kubernetes
INFO[0000] Successfully Deployed state file at [3-node-rancher-teststage.rkestate]
INFO[0000] [certificates] Generating admin certificates and kubeconfig
INFO[0000] Successfully Deployed state file at [3-node-rancher-teststage.rkestate]
INFO[0000] Building Kubernetes cluster
INFO[0000] [dialer] Setup tunnel for host [192.168.10.16]
INFO[0000] [dialer] Setup tunnel for host [192.168.10.17]
INFO[0000] [dialer] Setup tunnel for host [192.168.10.15]
INFO[0001] [network] No hosts added existing cluster, skipping port check
INFO[0001] [certificates] kube-apiserver certificate changed, force deploying certs
INFO[0001] [certificates] Deploying kubernetes certificates to Cluster nodes
INFO[0001] [certificates] Pulling image [rancher/rke-tools:v0.1.42] on host [192.168.10.16]
INFO[0001] [certificates] Pulling image [rancher/rke-tools:v0.1.42] on host [192.168.10.15]
INFO[0001] [certificates] Pulling image [rancher/rke-tools:v0.1.42] on host [192.168.10.17]
INFO[0006] [certificates] Successfully pulled image [rancher/rke-tools:v0.1.42] on host [192.168.10.17]
INFO[0006] [certificates] Successfully pulled image [rancher/rke-tools:v0.1.42] on host [192.168.10.16]
INFO[0006] [certificates] Successfully pulled image [rancher/rke-tools:v0.1.42] on host [192.168.10.15]
INFO[0012] [reconcile] Rebuilding and updating local kube config
INFO[0012] Successfully Deployed local admin kubeconfig at [kube_config_3-node-rancher-teststage.yml]
INFO[0012] [reconcile] host [192.168.10.15] is active master on the cluster
INFO[0012] [certificates] Successfully deployed kubernetes certificates to Cluster nodes
INFO[0012] [reconcile] Reconciling cluster state
INFO[0012] [reconcile] Check etcd hosts to be deleted
INFO[0012] [reconcile] Check etcd hosts to be added
INFO[0012] [reconcile] Rebuilding and updating local kube config
INFO[0012] Successfully Deployed local admin kubeconfig at [kube_config_3-node-rancher-teststage.yml]
INFO[0012] [reconcile] host [192.168.10.15] is active master on the cluster
INFO[0012] [reconcile] Reconciled cluster state successfully
INFO[0012] Pre-pulling kubernetes images
INFO[0012] [pre-deploy] Pulling image [rancher/hyperkube:v1.14.6-rancher1] on host [192.168.10.15]
INFO[0012] [pre-deploy] Pulling image [rancher/hyperkube:v1.14.6-rancher1] on host [192.168.10.17]
INFO[0012] [pre-deploy] Pulling image [rancher/hyperkube:v1.14.6-rancher1] on host [192.168.10.16]
INFO[0033] [pre-deploy] Successfully pulled image [rancher/hyperkube:v1.14.6-rancher1] on host [192.168.10.16]
INFO[0033] [pre-deploy] Successfully pulled image [rancher/hyperkube:v1.14.6-rancher1] on host [192.168.10.15]
INFO[0033] [pre-deploy] Successfully pulled image [rancher/hyperkube:v1.14.6-rancher1] on host [192.168.10.17]
INFO[0033] Kubernetes images pulled successfully
INFO[0033] [etcd] Building up etcd plane..
INFO[0033] [etcd] Pulling image [rancher/coreos-etcd:v3.3.10-rancher1] on host [192.168.10.15]
INFO[0036] [etcd] Successfully pulled image [rancher/coreos-etcd:v3.3.10-rancher1] on host [192.168.10.15]
INFO[0041] Waiting for [etcd] container to exit on host [192.168.10.15]
INFO[0042] [etcd] Successfully updated [etcd] container on host [192.168.10.15]
INFO[0042] [etcd] Saving snapshot [etcd-rolling-snapshots] on host [192.168.10.15]
INFO[0042] [remove/etcd-rolling-snapshots] Successfully removed container on host [192.168.10.15]
INFO[0042] [etcd] Successfully started [etcd-rolling-snapshots] container on host [192.168.10.15]
INFO[0048] [certificates] Successfully started [rke-bundle-cert] container on host [192.168.10.15]
INFO[0048] Waiting for [rke-bundle-cert] container to exit on host [192.168.10.15]
INFO[0048] Container [rke-bundle-cert] is still running on host [192.168.10.15]
INFO[0049] Waiting for [rke-bundle-cert] container to exit on host [192.168.10.15]
INFO[0049] [certificates] successfully saved certificate bundle [/opt/rke/etcd-snapshots//pki.bundle.tar.gz] on host [192.168.10.15]
INFO[0049] [etcd] Successfully started [rke-log-linker] container on host [192.168.10.15]
INFO[0049] [remove/rke-log-linker] Successfully removed container on host [192.168.10.15]
INFO[0049] [etcd] Pulling image [rancher/coreos-etcd:v3.3.10-rancher1] on host [192.168.10.16]
INFO[0052] [etcd] Successfully pulled image [rancher/coreos-etcd:v3.3.10-rancher1] on host [192.168.10.16]
INFO[0058] Waiting for [etcd] container to exit on host [192.168.10.16]
INFO[0058] [etcd] Successfully updated [etcd] container on host [192.168.10.16]
INFO[0058] [etcd] Saving snapshot [etcd-rolling-snapshots] on host [192.168.10.16]
INFO[0058] [remove/etcd-rolling-snapshots] Successfully removed container on host [192.168.10.16]
INFO[0059] [etcd] Successfully started [etcd-rolling-snapshots] container on host [192.168.10.16]
INFO[0064] [certificates] Successfully started [rke-bundle-cert] container on host [192.168.10.16]
INFO[0064] Waiting for [rke-bundle-cert] container to exit on host [192.168.10.16]
INFO[0064] Container [rke-bundle-cert] is still running on host [192.168.10.16]
INFO[0065] Waiting for [rke-bundle-cert] container to exit on host [192.168.10.16]
INFO[0065] [certificates] successfully saved certificate bundle [/opt/rke/etcd-snapshots//pki.bundle.tar.gz] on host [192.168.10.16]
INFO[0066] [etcd] Successfully started [rke-log-linker] container on host [192.168.10.16]
INFO[0066] [remove/rke-log-linker] Successfully removed container on host [192.168.10.16]
INFO[0066] [etcd] Pulling image [rancher/coreos-etcd:v3.3.10-rancher1] on host [192.168.10.17]
INFO[0069] [etcd] Successfully pulled image [rancher/coreos-etcd:v3.3.10-rancher1] on host [192.168.10.17]
INFO[0074] Waiting for [etcd] container to exit on host [192.168.10.17]
INFO[0074] [etcd] Successfully updated [etcd] container on host [192.168.10.17]
INFO[0074] [etcd] Saving snapshot [etcd-rolling-snapshots] on host [192.168.10.17]
INFO[0075] [remove/etcd-rolling-snapshots] Successfully removed container on host [192.168.10.17]
INFO[0075] [etcd] Successfully started [etcd-rolling-snapshots] container on host [192.168.10.17]
INFO[0080] [certificates] Successfully started [rke-bundle-cert] container on host [192.168.10.17]
INFO[0080] Waiting for [rke-bundle-cert] container to exit on host [192.168.10.17]
INFO[0080] Container [rke-bundle-cert] is still running on host [192.168.10.17]
INFO[0081] Waiting for [rke-bundle-cert] container to exit on host [192.168.10.17]
INFO[0081] [certificates] successfully saved certificate bundle [/opt/rke/etcd-snapshots//pki.bundle.tar.gz] on host [192.168.10.17]
INFO[0082] [etcd] Successfully started [rke-log-linker] container on host [192.168.10.17]
INFO[0082] [remove/rke-log-linker] Successfully removed container on host [192.168.10.17]
INFO[0082] [etcd] Successfully started etcd plane.. Checking etcd cluster health
INFO[0083] [controlplane] Building up Controller Plane..
INFO[0083] [remove/service-sidekick] Successfully removed container on host [192.168.10.15]
INFO[0083] [remove/service-sidekick] Successfully removed container on host [192.168.10.17]
INFO[0083] [remove/service-sidekick] Successfully removed container on host [192.168.10.16]
INFO[0083] Waiting for [kube-apiserver] container to exit on host [192.168.10.17]
INFO[0084] [controlplane] Successfully updated [kube-apiserver] container on host [192.168.10.17]
INFO[0084] [healthcheck] Start Healthcheck on service [kube-apiserver] on host [192.168.10.17]
INFO[0084] Waiting for [kube-apiserver] container to exit on host [192.168.10.16]
INFO[0084] Waiting for [kube-apiserver] container to exit on host [192.168.10.15]
INFO[0085] [controlplane] Successfully updated [kube-apiserver] container on host [192.168.10.15]
INFO[0085] [healthcheck] Start Healthcheck on service [kube-apiserver] on host [192.168.10.15]
INFO[0085] [controlplane] Successfully updated [kube-apiserver] container on host [192.168.10.16]
INFO[0085] [healthcheck] Start Healthcheck on service [kube-apiserver] on host [192.168.10.16]
INFO[0102] [healthcheck] service [kube-apiserver] on host [192.168.10.17] is healthy
INFO[0102] [controlplane] Successfully started [rke-log-linker] container on host [192.168.10.17]
INFO[0102] [remove/rke-log-linker] Successfully removed container on host [192.168.10.17]
INFO[0102] [healthcheck] service [kube-apiserver] on host [192.168.10.15] is healthy
INFO[0103] [controlplane] Successfully started [rke-log-linker] container on host [192.168.10.15]
INFO[0103] [remove/rke-log-linker] Successfully removed container on host [192.168.10.15]
INFO[0106] [healthcheck] service [kube-apiserver] on host [192.168.10.16] is healthy
INFO[0107] [controlplane] Successfully started [rke-log-linker] container on host [192.168.10.16]
INFO[0107] [remove/rke-log-linker] Successfully removed container on host [192.168.10.16]
INFO[0107] Waiting for [kube-controller-manager] container to exit on host [192.168.10.17]
INFO[0108] [controlplane] Successfully updated [kube-controller-manager] container on host [192.168.10.17]
INFO[0108] [healthcheck] Start Healthcheck on service [kube-controller-manager] on host [192.168.10.17]
INFO[0108] Waiting for [kube-controller-manager] container to exit on host [192.168.10.15]
INFO[0108] [controlplane] Successfully updated [kube-controller-manager] container on host [192.168.10.15]
INFO[0108] [healthcheck] Start Healthcheck on service [kube-controller-manager] on host [192.168.10.15]
INFO[0112] Waiting for [kube-controller-manager] container to exit on host [192.168.10.16]
INFO[0112] [controlplane] Successfully updated [kube-controller-manager] container on host [192.168.10.16]
INFO[0112] [healthcheck] Start Healthcheck on service [kube-controller-manager] on host [192.168.10.16]
INFO[0113] [healthcheck] service [kube-controller-manager] on host [192.168.10.17] is healthy
INFO[0114] [controlplane] Successfully started [rke-log-linker] container on host [192.168.10.17]
INFO[0114] [remove/rke-log-linker] Successfully removed container on host [192.168.10.17]
INFO[0114] [healthcheck] service [kube-controller-manager] on host [192.168.10.15] is healthy
INFO[0114] [controlplane] Successfully started [rke-log-linker] container on host [192.168.10.15]
INFO[0115] [remove/rke-log-linker] Successfully removed container on host [192.168.10.15]
INFO[0118] [healthcheck] service [kube-controller-manager] on host [192.168.10.16] is healthy
INFO[0118] [controlplane] Successfully started [rke-log-linker] container on host [192.168.10.16]
INFO[0118] [remove/rke-log-linker] Successfully removed container on host [192.168.10.16]
INFO[0119] Waiting for [kube-scheduler] container to exit on host [192.168.10.17]
INFO[0119] [controlplane] Successfully updated [kube-scheduler] container on host [192.168.10.17]
INFO[0119] [healthcheck] Start Healthcheck on service [kube-scheduler] on host [192.168.10.17]
INFO[0120] Waiting for [kube-scheduler] container to exit on host [192.168.10.15]
INFO[0120] [controlplane] Successfully updated [kube-scheduler] container on host [192.168.10.15]
INFO[0120] [healthcheck] Start Healthcheck on service [kube-scheduler] on host [192.168.10.15]
INFO[0124] Waiting for [kube-scheduler] container to exit on host [192.168.10.16]
INFO[0124] [controlplane] Successfully updated [kube-scheduler] container on host [192.168.10.16]
INFO[0124] [healthcheck] Start Healthcheck on service [kube-scheduler] on host [192.168.10.16]
INFO[0125] [healthcheck] service [kube-scheduler] on host [192.168.10.17] is healthy
INFO[0125] [controlplane] Successfully started [rke-log-linker] container on host [192.168.10.17]
INFO[0125] [remove/rke-log-linker] Successfully removed container on host [192.168.10.17]
INFO[0126] [healthcheck] service [kube-scheduler] on host [192.168.10.15] is healthy
INFO[0126] [controlplane] Successfully started [rke-log-linker] container on host [192.168.10.15]
INFO[0126] [remove/rke-log-linker] Successfully removed container on host [192.168.10.15]
INFO[0129] [healthcheck] service [kube-scheduler] on host [192.168.10.16] is healthy
INFO[0130] [controlplane] Successfully started [rke-log-linker] container on host [192.168.10.16]
INFO[0130] [remove/rke-log-linker] Successfully removed container on host [192.168.10.16]
INFO[0130] [controlplane] Successfully started Controller Plane..
INFO[0130] [authz] Creating rke-job-deployer ServiceAccount
INFO[0130] [authz] rke-job-deployer ServiceAccount created successfully
INFO[0130] [authz] Creating system:node ClusterRoleBinding
INFO[0130] [authz] system:node ClusterRoleBinding created successfully
INFO[0130] [authz] Creating kube-apiserver proxy ClusterRole and ClusterRoleBinding
INFO[0130] [authz] kube-apiserver proxy ClusterRole and ClusterRoleBinding created successfully
INFO[0130] Successfully Deployed state file at [3-node-rancher-teststage.rkestate]
INFO[0130] [state] Saving full cluster state to Kubernetes
INFO[0130] [state] Successfully Saved full cluster state to Kubernetes ConfigMap: cluster-state
INFO[0130] [worker] Building up Worker Plane..
INFO[0130] [sidekick] Sidekick container already created on host [192.168.10.15]
INFO[0130] [sidekick] Sidekick container already created on host [192.168.10.17]
INFO[0130] [sidekick] Sidekick container already created on host [192.168.10.16]
INFO[0130] Waiting for [kubelet] container to exit on host [192.168.10.17]
INFO[0130] Waiting for [kubelet] container to exit on host [192.168.10.15]
INFO[0130] Waiting for [kubelet] container to exit on host [192.168.10.16]
INFO[0130] [worker] Successfully updated [kubelet] container on host [192.168.10.17]
INFO[0131] [worker] Successfully updated [kubelet] container on host [192.168.10.15]
INFO[0131] [healthcheck] Start Healthcheck on service [kubelet] on host [192.168.10.17]
INFO[0131] [worker] Successfully updated [kubelet] container on host [192.168.10.16]
INFO[0131] [healthcheck] Start Healthcheck on service [kubelet] on host [192.168.10.15]
INFO[0131] [healthcheck] Start Healthcheck on service [kubelet] on host [192.168.10.16]
INFO[0136] [healthcheck] service [kubelet] on host [192.168.10.15] is healthy
INFO[0139] [worker] Successfully started [rke-log-linker] container on host [192.168.10.15]
INFO[0139] [remove/rke-log-linker] Successfully removed container on host [192.168.10.15]
INFO[0141] [healthcheck] service [kubelet] on host [192.168.10.16] is healthy
INFO[0142] [healthcheck] service [kubelet] on host [192.168.10.17] is healthy
INFO[0142] [worker] Successfully started [rke-log-linker] container on host [192.168.10.17]
INFO[0142] [worker] Successfully started [rke-log-linker] container on host [192.168.10.16]
INFO[0143] [remove/rke-log-linker] Successfully removed container on host [192.168.10.17]
INFO[0143] [remove/rke-log-linker] Successfully removed container on host [192.168.10.16]
INFO[0144] Waiting for [kube-proxy] container to exit on host [192.168.10.15]
INFO[0145] [worker] Successfully updated [kube-proxy] container on host [192.168.10.15]
INFO[0145] [healthcheck] Start Healthcheck on service [kube-proxy] on host [192.168.10.15]
INFO[0148] Waiting for [kube-proxy] container to exit on host [192.168.10.17]
INFO[0148] Waiting for [kube-proxy] container to exit on host [192.168.10.16]
INFO[0148] [worker] Successfully updated [kube-proxy] container on host [192.168.10.17]
INFO[0148] [healthcheck] Start Healthcheck on service [kube-proxy] on host [192.168.10.17]
INFO[0148] [worker] Successfully updated [kube-proxy] container on host [192.168.10.16]
INFO[0149] [healthcheck] Start Healthcheck on service [kube-proxy] on host [192.168.10.16]
INFO[0151] [healthcheck] service [kube-proxy] on host [192.168.10.15] is healthy
INFO[0151] [worker] Successfully started [rke-log-linker] container on host [192.168.10.15]
INFO[0151] [remove/rke-log-linker] Successfully removed container on host [192.168.10.15]
INFO[0154] [healthcheck] service [kube-proxy] on host [192.168.10.16] is healthy
INFO[0154] [healthcheck] service [kube-proxy] on host [192.168.10.17] is healthy
INFO[0155] [worker] Successfully started [rke-log-linker] container on host [192.168.10.16]
INFO[0155] [worker] Successfully started [rke-log-linker] container on host [192.168.10.17]
INFO[0155] [remove/rke-log-linker] Successfully removed container on host [192.168.10.16]
INFO[0156] [remove/rke-log-linker] Successfully removed container on host [192.168.10.17]
INFO[0156] [worker] Successfully started Worker Plane..
INFO[0156] [cleanup] Successfully started [rke-log-cleaner] container on host [192.168.10.15]
INFO[0156] [cleanup] Successfully started [rke-log-cleaner] container on host [192.168.10.17]
INFO[0156] [cleanup] Successfully started [rke-log-cleaner] container on host [192.168.10.16]
INFO[0156] [remove/rke-log-cleaner] Successfully removed container on host [192.168.10.15]
INFO[0156] [remove/rke-log-cleaner] Successfully removed container on host [192.168.10.17]
INFO[0156] [remove/rke-log-cleaner] Successfully removed container on host [192.168.10.16]
INFO[0156] [sync] Syncing nodes Labels and Taints
INFO[0156] [sync] Successfully synced nodes Labels and Taints
INFO[0156] [network] Setting up network plugin: canal
INFO[0156] [addons] Saving ConfigMap for addon rke-network-plugin to Kubernetes
INFO[0156] [addons] Successfully saved ConfigMap for addon rke-network-plugin to Kubernetes
INFO[0156] [addons] Executing deploy job rke-network-plugin
INFO[0167] [addons] Setting up coredns
INFO[0167] [addons] Saving ConfigMap for addon rke-coredns-addon to Kubernetes
INFO[0167] [addons] Successfully saved ConfigMap for addon rke-coredns-addon to Kubernetes
INFO[0167] [addons] Executing deploy job rke-coredns-addon
INFO[0172] [addons] CoreDNS deployed successfully..
INFO[0172] [dns] DNS provider coredns deployed successfully
INFO[0172] [addons] Setting up Metrics Server
INFO[0172] [addons] Saving ConfigMap for addon rke-metrics-addon to Kubernetes
INFO[0172] [addons] Successfully saved ConfigMap for addon rke-metrics-addon to Kubernetes
INFO[0172] [addons] Executing deploy job rke-metrics-addon
INFO[0182] [addons] Metrics Server deployed successfully
INFO[0182] [ingress] Setting up nginx ingress controller
INFO[0182] [addons] Saving ConfigMap for addon rke-ingress-controller to Kubernetes
INFO[0182] [addons] Successfully saved ConfigMap for addon rke-ingress-controller to Kubernetes
INFO[0182] [addons] Executing deploy job rke-ingress-controller
INFO[0192] [ingress] ingress controller nginx deployed successfully
INFO[0192] [addons] Setting up user addons
INFO[0192] [addons] no user addons defined
INFO[0192] Finished building Kubernetes cluster successfully
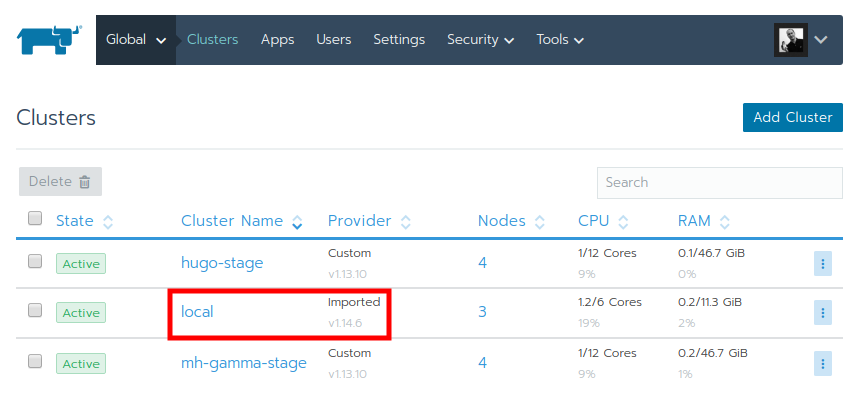
After a successful run of rke, the local cluster now shows with the new Kubernetes version in the UI:
Updated February 12th 2021:
If the Kubernetes certificates expired in the background, rke might not be able to upgrade the cluster. The certificates need to be renewed (rotated) first. See How to solve Kubernetes upgrade in Rancher 2 failing with remote error: tls: bad certificate.
helm2 is meanwhile deprecated and basically doesn't work anymore. Upgrade to helm3! See Rancher 2 upgrade gone bad: Management cluster down (a.k.a. you really need to ditch helm v2 and use helm v3).
Manuel from wrote on Dec 6th, 2019:
After some research I found the logs.
DEBU[0057] Failed to get /health for host [XXX.XXX.XXX.XXX]: Get https://XXX.XXX.XXX.XXX:2379/health: remote error: tls: bad certificate
This is the exact same issue.
https://github.com/rancher/rke/issues/1244
I will try to fix it from there. Thanks for the help :)
Claudio Kuenzler from Switzerland wrote on Dec 6th, 2019:
Hello Manuel,
FATA[0089] [etcd] Failed to bring up Etcd Plane: [etcd] Etcd Cluster is not healthy
That doesn't sound so good. You might have to clean up/reset the Rancher Kubernetes node as you suggested - but I'm not certain. It's definitely the last resort. Maybe a full cluster restart will help to re-establish a working etcd cluster (meaning: restart of all nodes). Unfortunately the rke logs don't show the reason why this fails. Maybe you can see more on this particular node in the Docker logs. You should also write this in the Rancher community forums, maybe someone already had the same problem.
Manuel from wrote on Dec 6th, 2019:
After opening the port 6443 the installation proceeded but I get the following error:
INFO[0043] [etcd] Successfully started etcd plane.. Checking etcd cluster health
FATA[0089] [etcd] Failed to bring up Etcd Plane: [etcd] Etcd Cluster is not healthy
Do I need to clean the Nodes? I have all ports open now.
Sorry for the inconveniences :(
Claudio Kuenzler from Switzerland wrote on Dec 4th, 2019:
Hi Manuel, I just verified this with a Kubernetes certificate rotate from rke and capturing a tcdump while doing this. The node, where you launch rke accesses ports 22 (SSH) and 6443 (Kubernetes API) of the cluster nodes. So make sure both of these ports are open from the host with rke to the Kubernetes cluster nodes.
Manuel from wrote on Dec 3rd, 2019:
Hello Claudio. Thank you for the quick response.
We currently have a Rancher HA deployment (3 nodes + 1 load-balancer) installed with the official docs. I use a ssh bridge with the load-balancer to connect to the nodes behind. Then in my computer I execute RKE pointing to the ports I opened using the bridge. That's how I installed the first time K8s in the nodes. I can confirm I am using the right YAML, the nodes are working and I have ssh access to them.
The problem seems to be a firewall block. My computer should be able to check that port (6443)? Or it's something else I am missing?
Thanks again :)
Claudio Kuenzler from Switzerland wrote on Dec 3rd, 2019:
Manuel, I could only assume one of these:
- firewall blocks (use tcpdump)?
- wrong (or outdated) yaml used?
- issues on the target host(s)?
- no ssh access / wrong ssh user?
Besides that pretty difficult to tell without seeing your environment ;)
Manuel from wrote on Dec 3rd, 2019:
RKE Version: v0.3.1
local Cluster Kubernetes version: v1.13.5
When I execute RKE up, I get the following error.
INFO[0044] [network] Checking KubeAPI port Control Plane hosts
FATA[0044] [network] Can't access KubeAPI port [6443] on Control Plane host: xxx.xxx.xxx.xxx
Do you know a way to fix this? Thank you in advance.

AI AWS Android Ansible Apache Apple Atlassian BSD Backup Bash Bluecoat CMS Chef Cloud Coding Consul Containers CouchDB DB DNS Databases Docker ELK Elasticsearch Filebeat FreeBSD Galera Git GlusterFS Grafana Graphics HAProxy HTML Hacks Hardware Icinga Influx Internet Java KVM Kibana Kodi Kubernetes LVM LXC Linux Logstash Mac Macintosh Mail MariaDB Minio MongoDB Monitoring Multimedia MySQL NFS Nagios Network Nginx OSSEC OTRS Observability Office OpenSearch PHP Perl Personal PostgreSQL PowerDNS Proxmox Proxy Python Rancher Rant Redis Roundcube SSL Samba Seafile Security Shell SmartOS Solaris Surveillance Systemd TLS Tomcat Ubuntu Unix VMware Varnish Virtualization Windows Wireless Wordpress Wyse ZFS Znuny Zoneminder
{kind=link}