
For the last couple of days I tried to understand and solve a problem where Google was unable to index pages from a Wordpress shop (using Woocommerce) selling Kombucha Scoby, Milk Kefir, Water Kefir, Mesophilic Yoghurt Starters and Sourdough starters. All these non-indexed pages were marked as "User-selected duplicate" in Google's Search Console:
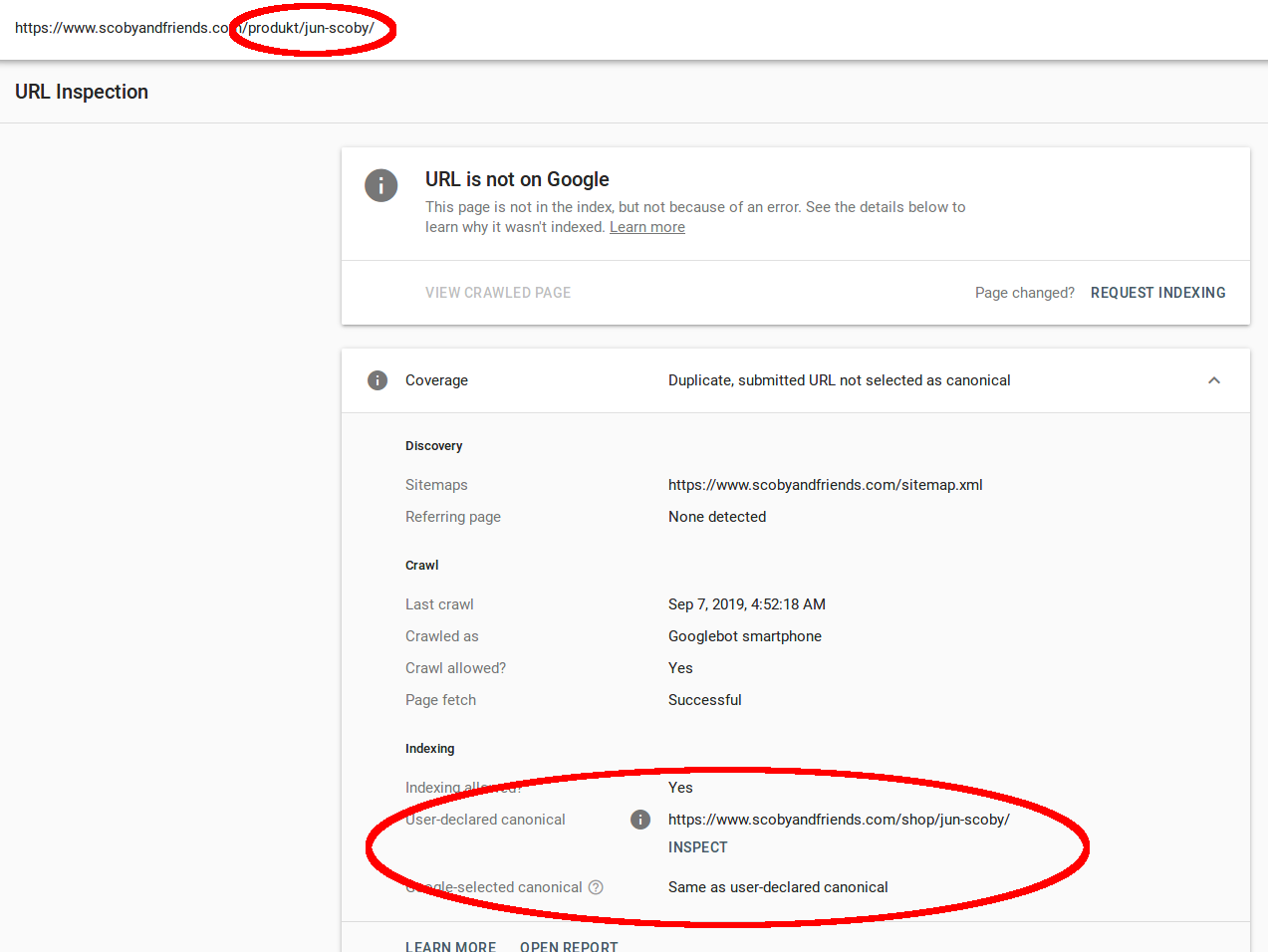
As one can see in the screenshot, the requested URL contains the German word "produkt" (translated from "product") and shows the manually translated German description of the product. This means the content is definitely different than the English version (different words to say at least). After further investigation it turned out that all the German translated products were excluded from Google's indexing. All with the same hint that these pages/products were "Duplicate, submitted URL not selected as canonical". But where does this canonical link come from, why does Google believe that the German page is a duplicate?
When I recently created a new version of this blog, I learned a lot about new SEO technologies, social media sharing (hint: OG meta tags) and also about canonical linking. When duplicating a page or just the content, for whatever reason, all the duplicated pages should contain a <link rel='canonical' href='URL-to-original-content' /> in the HTML head. This helps Google to identify the real source of the content and helps to avoid indexing problems.
Back to the problem with the WPML translated pages. Even after triple-checking the source code, no such canonical link could be found - yet Google still insisted the pages are duplicates.
Finally today a very important hint in the WPML support forums was discovered:
what might cause this message that you are getting on the Google console is the following. In WPML -> Languages -> Browser language redirect, you have selected the option 'Always redirect visitors based on browser language (redirect to the home page if translations are missing)'. So this might be the reason that Google interprets the translations as duplicated content.
This actually makes absolute sense! Of course the current settings were immediately verified. And, indeed, the browser redirect was enabled:
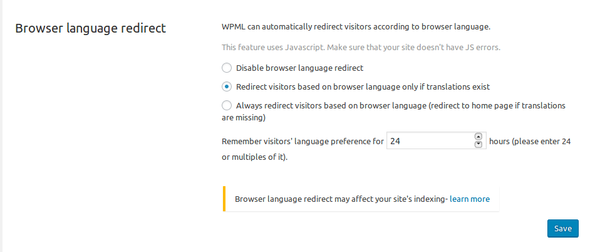
(There's even a warning showing up concerning site indexing!)
Google's indexing bot crawls the websites without specifying a browser language (using the Accept-Language HTTP header). From Search Console Help:
If you prefer to dynamically change content or reroute the user based on language settings, be aware that Google might not find and crawl all your variations. This is because the Googlebot crawler usually originates from the USA. In addition, the crawler sends HTTP requests without setting Accept-Language in the request header.
What happened, technically speaking, was the following:
This WPML setting has now been changed (in Wordpress Admin -> WPML -> Languages -> Browser language redirect) to handle this correctly:
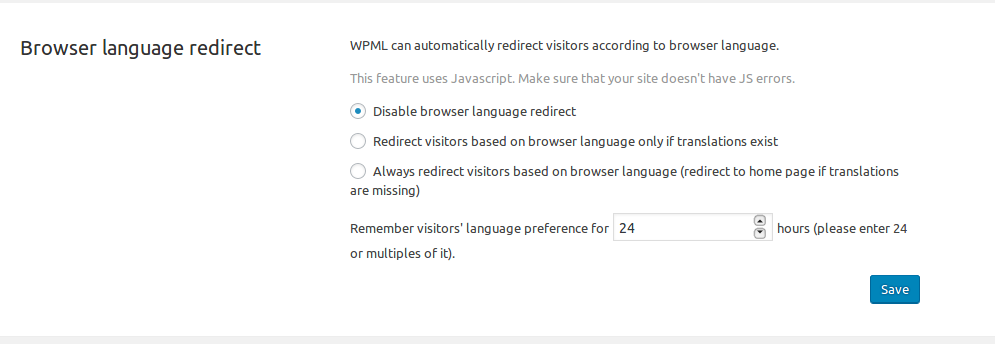
Now it's a question of patience and check the results in Google's Search Console in (more or less) 3 days. This article will get a short update once the solution can be confirmed.
Alex from wrote on Nov 25th, 2019:
Claudio, great research! I have the same issue, but disabling browser redirects not helped. WPML still makes a duplicate page with trailing slash at the end of URL

AI AWS Android Ansible Apache Apple Atlassian BSD Backup Bash Bluecoat CMS Chef Cloud Coding Consul Containers CouchDB DB DNS Databases Docker ELK Elasticsearch Filebeat FreeBSD Galera Git GlusterFS Grafana Graphics HAProxy HTML Hacks Hardware Icinga Influx Internet Java KVM Kibana Kodi Kubernetes LVM LXC Linux Logstash Mac Macintosh Mail MariaDB Minio MongoDB Monitoring Multimedia MySQL NFS Nagios Network Nginx OSSEC OTRS Observability Office OpenSearch PHP Perl Personal PostgreSQL PowerDNS Proxmox Proxy Python Rancher Rant Redis Roundcube SSL Samba Seafile Security Shell SmartOS Solaris Surveillance Systemd TLS Tomcat Ubuntu Unix VMware Varnish Virtualization Windows Wireless Wordpress Wyse ZFS Znuny Zoneminder