
Kubernetes has one major component, which must run to guarantee a working cluster: The control plane. etcd is part of the control plane component and as etcd is very picky about fault tolerance, it may even be considered the most important one. Not in terms of importance per se, but in terms of "you really don't want this component to fail!".
etcd is, simply explained, the database behind the Kubernetes cluster. Or as the official documentation describes:
Consistent and highly-available key value store used as Kubernetes' backing store for all cluster data.
etcd is mostly used in a clustered setup, consisting of multiple etcd members. In order to have a fault tolerance calculation, etcd works in uneven numbers (see Why an odd number of cluster members in the etcd FAQ).
A single etcd server is the minimum - but in case of a problem on this etcd server, the whole Kubernetes cluster will be down (no high availability). The next bigger setup would be a cluster consisting of three members. This cluster is now fully HA - if the members are running on separate nodes and better even in separate locations.
In a 3 member etcd cluster, 2 members must still be working or the whole etcd cluster is defective - and with it your Kubernetes cluster, too. This fact should ring some alarms: What if you run your cluster across two datacenters? Well the question is whether you're lucky or not.
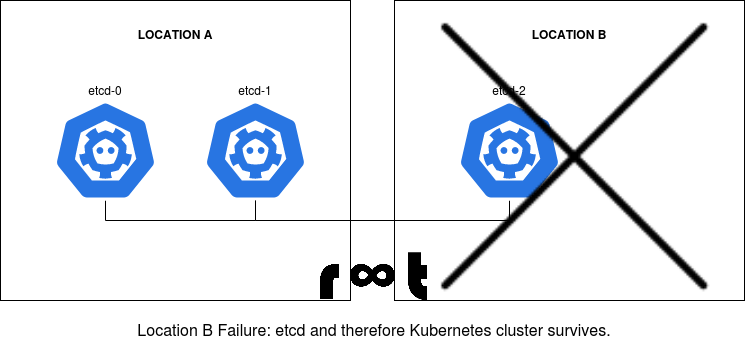
In the above scenario, location B failed and one member of the etcd cluster is lost. The cluster however will continue to run happily with the remaining two members.
But if you've been long enough in this profession of magic (IT), you forcibly know Murphy's law and location A will most likely be hit. What happens in this case?
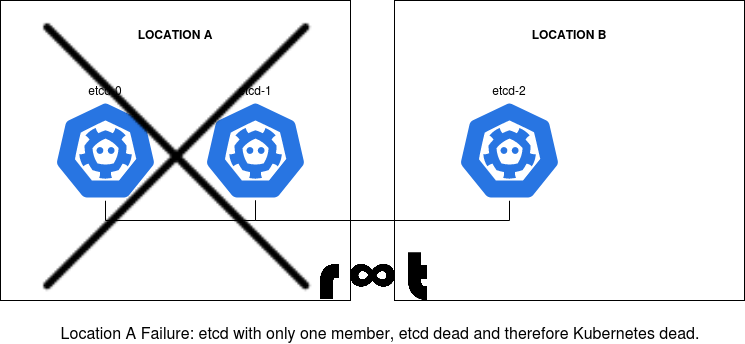
Basically said: You're offline now. Location A hosted two members of the three member etcd cluster. The majority of the etcd cluster is down and therefore the whole Kubernetes cluster.
Increasing the number of nodes hosting an etcd member would sound like a plausible solution.
Note: Although there's no hard limit on a etcd cluster size, it is advised not to go above a 5 member cluster for performance reasons.
Let's assume a 5 member etcd cluster was built. In any case of failure (location A or location B), at least two members will remain working and this should keep the cluster alive... right? No!
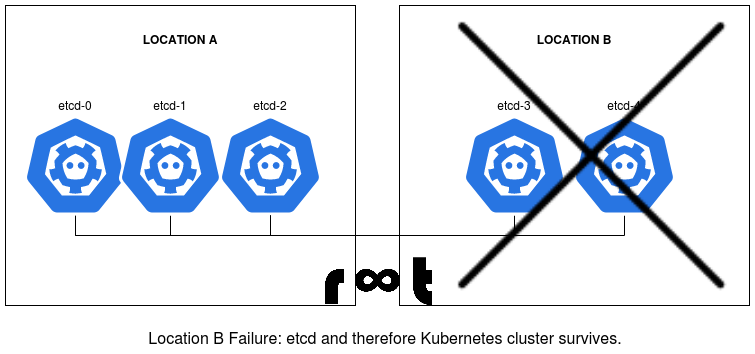
In case of a location B failure, the cluster remains alive. This is due to same fact as in the three member cluster: The majority of the cluster is alive.
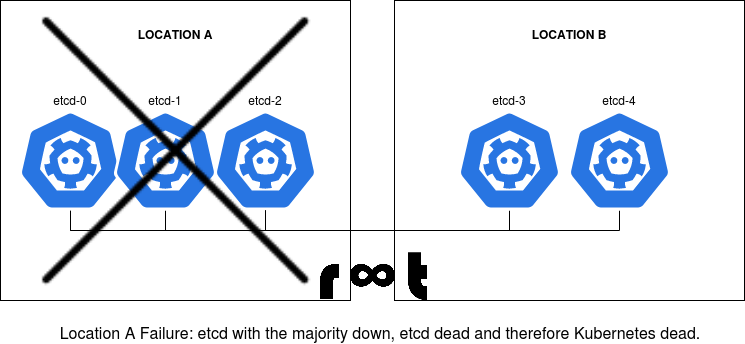
But if location A fails, the cluster faces the same problem again: The majority of the nodes is down - therefore the whole cluster is down and it tears Kubernetes with it.
The reason for this can be found in the fault tolerance calculation of the cluster: A quorum is always needed. The following table (taken from the etcd FAQ) shows very nicely, how an increased cluster size has an effect on fault tolerance (= how many members can be down allowing the etcd to still work correctly):
| Cluster Size |
Majority | Fault Tolerance |
| 1 | 1 | 0 |
| 2 | 2 | 0 |
| 3 | 2 | 1 |
| 4 | 3 | 1 |
| 5 |
3 |
2 |
| 6 |
4 |
2 |
| 7 |
4 |
3 |
| 8 |
5 |
3 |
| 9 |
5 |
4 |
The list could go on an on - but you probably get the idea: There will always be a risk that location A (the location with the higher number of etcd cluster members) will fail and in this case etcd as a whole will fail.
Many enterprises running most or some of their servers on premise use a two location or two data center setup. If you are running servers or services in the cloud, you're most likely familiar to availability zones (AZ) already. AWS (mostly) offers three availability zones per region, so does Azure (mostly) and maybe also other providers such as Google or Digitalocean (I did not check on these two). Here this problem can be solved by setting up the Kubernetes cluster and therefore the etcd nodes in separate availability zones.
But how does that help an on-premise setup with two data centers? A lot! By simply creating a new node in the cloud and adding it as an etcd node into the Kubernetes cluster will ensure your cluster now runs in three different locations. And most cloud providers even support VPN tunnels, so you can be sure to secure your traffic and use internal IP addressing:
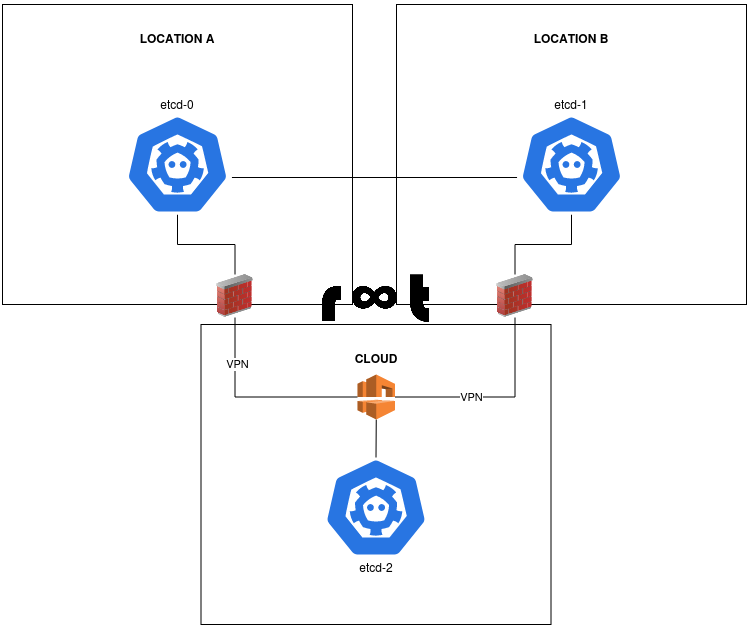
In case of a location A failure, the majority of etcd nodes are still up. The same happens in a scenario when location B is down. And yet again the same situation when the "remote" location in the cloud is hit (or Internet connectivity is down).
To reduce costs of the cloud instance, the node can be added as etcd member only. It does not have to be a worker (which probably would not make much sense in an on-premise setup anyway) and not even a control plane node.
No comments yet.

AI AWS Android Ansible Apache Apple Atlassian BSD Backup Bash Bluecoat CMS Chef Cloud Coding Consul Containers CouchDB DB DNS Databases Docker ELK Elasticsearch Filebeat FreeBSD Galera Git GlusterFS Grafana Graphics HAProxy HTML Hacks Hardware Icinga Influx Internet Java KVM Kibana Kodi Kubernetes LVM LXC Linux Logstash Mac Macintosh Mail MariaDB Minio MongoDB Monitoring Multimedia MySQL NFS Nagios Network Nginx OSSEC OTRS Observability Office OpenSearch PHP Perl Personal PostgreSQL PowerDNS Proxmox Proxy Python Rancher Rant Redis Roundcube SSL Samba Seafile Security Shell SmartOS Solaris Surveillance Systemd TLS Tomcat Ubuntu Unix VMware Varnish Virtualization Windows Wireless Wordpress Wyse ZFS Znuny Zoneminder