
Whenever a Kubernetes node runs into resource problems, it tries to recover itself by "evicting" pods and the underlying containers. This process is called the node-pressure eviction.
The node-pressure eviction can be caused for different reasons. The most common reason is that the Kubernetes node ran into a resource limit, defined by (pre-defined) thresholds. These thresholds include:
Hitting one of the thresholds results in a "pressure" condition. In Rancher's UI the relevant pressure condition is then shown at the Nodes overview.
Basically Kubernetes does some housekeeping (no kidding, the actual term of the eviction monitoring interval is called housekeeping-interval) and evicts pods whenever a pressure condition is detected.
This housekeeping "evicts" (terminates) a pod and the containers building the pod - but does not delete the pod. Kubernetes, by default, also doesn't make a real difference between very important and not at all important pods - it has one job and this is to reclaim resources. Workloads managed by a workload resource, such as StatefulSet (typically 1 pod per node) or Deployment, will automatically create new pods and replace the evicted pods.
Although the evicted pods are terminated and (should) are not use any resources from the node anymore, they are still hanging around - and Kubernetes still manages them. After a while, and with a growing number of evicted pods, this can lead to increased required resources within the Kubernetes management itself.
Obviously there are a couple of ways. When using Rancher as on-top-layer to manage Kubernetes, these evicted pods can be seen in the UI. They appear as red warning icons:
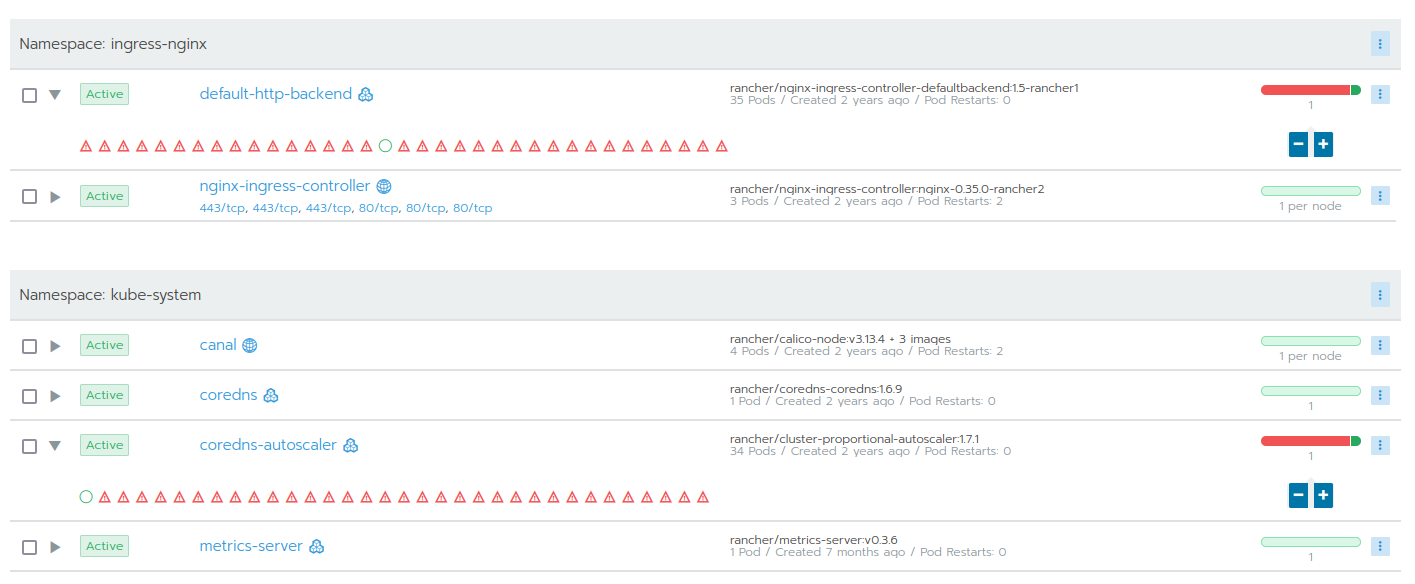
As Rancher also allows direct access to the Kubernetes layer using kubectl, the evicted pods can also be seen on the command line:
ck@mintp ~ $ kubectl get pods --insecure-skip-tls-verify=true --all-namespaces | grep Evicted
ingress-nginx default-http-backend-5f8666475c-2h5s8 0/1 Evicted 0 7d4h
ingress-nginx default-http-backend-5f8666475c-2xb56 0/1 Evicted 0 7d4h
ingress-nginx default-http-backend-5f8666475c-56xk9 0/1 Evicted 0 7d4h
ingress-nginx default-http-backend-5f8666475c-5kjlc 0/1 Evicted 0 7d4h
ingress-nginx default-http-backend-5f8666475c-5lhjl 0/1 Evicted 0 7d4h
[...]
kube-system coredns-autoscaler-7768d884b9-vmcll 0/1 Evicted 0 7d4h
kube-system coredns-autoscaler-7768d884b9-x2sgx 0/1 Evicted 0 7d4h
kube-system coredns-autoscaler-7768d884b9-xqgzr 0/1 Evicted 0 7d4h
kube-system coredns-autoscaler-7768d884b9-zdhpc 0/1 Evicted 0 7d4h
ck@mintp ~ $ kubectl get pods --insecure-skip-tls-verify=true --all-namespaces | grep Evicted -c
67
In this particular situation, a total of 67 pods are showing up as Evicted.
But seriously, who is manually checking for evicted pods in the Rancher UI or via kubectl every other day? Can't this be automatically monitored? Yes - of course.
The check_rancher2 script is an open source monitoring plugin to monitor, you guessed it, Kubernetes environments managed by Rancher 2. The -t parameter allows all kinds of check types, including the -t pod check. This monitors all pods within a given project (using the syntax cluster-identifier:project-identifier):
ckadm@mintp ~ $ ./check_rancher2.sh -H rancher.example.com -U token-xxxxx -P "secret" -S -t pod -p c-xxxxx:p-xxxxx
CHECK_RANCHER2 CRITICAL - Pod default-http-backend-5f8666475c-2h5s8 is failed - Pod default-http-backend-5f8666475c-2xb56 is failed - Pod default-http-backend-5f8666475c-56xk9 is failed - Pod default-http-backend-5f8666475c-5kjlc is failed - Pod default-http-backend-5f8666475c-5lhjl is failed - Pod default-http-backend-5f8666475c-657jn is failed - Pod default-http-backend-5f8666475c-6hqcz is failed - Pod default-http-backend-5f8666475c-6lvqz is failed - Pod default-http-backend-5f8666475c-79q74 is failed - Pod default-http-backend-5f8666475c-7qwv5 is failed - Pod default-http-backend-5f8666475c-88v74 is failed - Pod default-http-backend-5f8666475c-8hjpp is failed - Pod default-http-backend-5f8666475c-8jzpb is failed - Pod default-http-backend-5f8666475c-bf7kz is failed - Pod default-http-backend-5f8666475c-bkvw9 is failed - Pod default-http-backend-5f8666475c-bx4gh is failed - Pod default-http-backend-5f8666475c-c9pkp is failed - Pod default-http-backend-5f8666475c-dh5sv is failed - Pod default-http-backend-5f8666475c-g2rwd is failed - Pod default-http-backend-5f8666475c-gqbvj is failed - Pod default-http-backend-5f8666475c-h726v is failed - Pod default-http-backend-5f8666475c-hlpvx is failed - Pod default-http-backend-5f8666475c-jvdz4 is failed - Pod default-http-backend-5f8666475c-kb9rx is failed - Pod default-http-backend-5f8666475c-kpf5l is failed - Pod default-http-backend-5f8666475c-l4zn7 is failed - Pod default-http-backend-5f8666475c-n5b2f is failed - Pod default-http-backend-5f8666475c-pjtzn is failed - Pod default-http-backend-5f8666475c-pqj2t is failed - Pod default-http-backend-5f8666475c-r2w4k is failed - Pod default-http-backend-5f8666475c-t6pb8 is failed - Pod default-http-backend-5f8666475c-v2mbh is failed - Pod default-http-backend-5f8666475c-v5jqt is failed - Pod default-http-backend-5f8666475c-z89tc is failed - Pod coredns-autoscaler-7768d884b9-2tc9z is failed - Pod coredns-autoscaler-7768d884b9-42kts is failed - Pod coredns-autoscaler-7768d884b9-4vmxz is failed - Pod coredns-autoscaler-7768d884b9-67fzg is failed - Pod coredns-autoscaler-7768d884b9-7c9wc is failed - Pod coredns-autoscaler-7768d884b9-8f98v is failed - Pod coredns-autoscaler-7768d884b9-9h5r9 is failed - Pod coredns-autoscaler-7768d884b9-9lt9s is failed - Pod coredns-autoscaler-7768d884b9-d65ls is failed - Pod coredns-autoscaler-7768d884b9-dzxbf is failed - Pod coredns-autoscaler-7768d884b9-fqp6m is failed - Pod coredns-autoscaler-7768d884b9-g486v is failed - Pod coredns-autoscaler-7768d884b9-gkdhg is failed - Pod coredns-autoscaler-7768d884b9-hxnw6 is failed - Pod coredns-autoscaler-7768d884b9-k77fm is failed - Pod coredns-autoscaler-7768d884b9-l4f6l is failed - Pod coredns-autoscaler-7768d884b9-lhr4v is failed - Pod coredns-autoscaler-7768d884b9-lvwhr is failed - Pod coredns-autoscaler-7768d884b9-mff6l is failed - Pod coredns-autoscaler-7768d884b9-mlfdd is failed - Pod coredns-autoscaler-7768d884b9-p55ks is failed - Pod coredns-autoscaler-7768d884b9-qktxj is failed - Pod coredns-autoscaler-7768d884b9-r8zxr is failed - Pod coredns-autoscaler-7768d884b9-rkhgn is failed - Pod coredns-autoscaler-7768d884b9-shtmq is failed - Pod coredns-autoscaler-7768d884b9-sk2hv is failed - Pod coredns-autoscaler-7768d884b9-v45x9 is failed - Pod coredns-autoscaler-7768d884b9-vc8wb is failed - Pod coredns-autoscaler-7768d884b9-vdjt2 is failed - Pod coredns-autoscaler-7768d884b9-vmcll is failed - Pod coredns-autoscaler-7768d884b9-x2sgx is failed - Pod coredns-autoscaler-7768d884b9-xqgzr is failed - Pod coredns-autoscaler-7768d884b9-zdhpc is failed -|'pods_total'=94;;;; 'pods_errors'=67;;;;
As the output shows, the plugin returns 67 pods as failed. That's the exact same number the manual evicted pod lookup from before.
By integrating this check into a classical monitoring software, such as Nagios or Icinga, the "pods health" check can be added as service. The following example shows an integration of the check into Icinga 2:
# check rancher2 all pods in cluster example in project system
object Service "Rancher2 Example Cluster System Pods" {
import "generic-service"
host_name = "rancher.example.com"
check_command = "check_rancher2"
vars.rancher2_username = "token-xxxxx"
vars.rancher2_password = "secret"
vars.rancher2_ssl = true
vars.rancher2_type = "pod"
vars.rancher2_project = "c-xxxxx:p-xxxxx"
}
This then results in an alert when evicted (failed) pods show up.
This question of course comes up: Why isn't Kubernetes itself removing these evicted pods? Actually Kubernetes would take care of it, but only after a certain number of evicted pods.
The responsible part of Kubernetes for deleting evicted pods is the kube-controller-manager. This container/process accepts a parameter which defines the number of evicted pods before the "garbage collection" of Kubernetes kicks in and starts to delete evicted pods:
--terminated-pod-gc-threshold int32 Default: 12500
Number of terminated pods that can exist before the terminated pod garbage collector starts deleting terminated pods. If <= 0, the terminated pod garbage collector is disabled.
The Kubernetes default is set to a very high limit: 12500. That means that after 12500 pods were evicted, the garbage collection would start and evicted pods would be deleted. That might be OK in a huge cluster with hundreds of nodes, but in small clusters this number is way too high.
But how are the limits in Rancher? Are the defaults overwritten? This can be verified by checking (docker inspect) the startup command of the kube-controller-manager container on Rancher managed Kubernetes nodes:
root@kubenode1:~# docker inspect $(docker ps|grep kube-controller-manager | awk '{print $1}')
[
{
"Id": "cdf8f579aba6c403901030c3599db02008b546095de6dbb63081098fd37ac6d2",
"Created": "2021-02-22T14:16:21.177129492Z",
"Path": "/opt/rke-tools/entrypoint.sh",
"Args": [
"kube-controller-manager",
"--service-account-private-key-file=/etc/kubernetes/ssl/kube-service-account-token-key.pem",
"--service-cluster-ip-range=10.43.0.0/16",
"--configure-cloud-routes=false",
"--enable-hostpath-provisioner=false",
"--cluster-cidr=10.42.0.0/16",
"--allow-untagged-cloud=true",
"--address=0.0.0.0",
"--node-monitor-grace-period=40s",
"--pod-eviction-timeout=5m0s",
"--terminated-pod-gc-threshold=1000",
"--v=2",
"--root-ca-file=/etc/kubernetes/ssl/kube-ca.pem",
"--profiling=false",
"--allocate-node-cidrs=true",
"--leader-elect=true",
"--cloud-provider=",
"--kubeconfig=/etc/kubernetes/ssl/kubecfg-kube-controller-manager.yaml",
"--use-service-account-credentials=true"
],
"State": {
"Status": "running",
"Running": true,
"Paused": false,
"Restarting": false,
"OOMKilled": false,
"Dead": false,
"Pid": 5598,
"ExitCode": 0,
"Error": "",
"StartedAt": "2021-09-13T11:17:42.79952794Z",
"FinishedAt": "2021-09-13T11:17:42.003965919Z"
},
[...]
Here the --terminated-pod-gc-threshold parameter is set to 1000. This means that within a Rancher managed Kubernetes cluster, the threshold is set to 1000 evicted pods - and then these pods should be automatically deleted.
If you don't want to wait until the garbage collection threshold is reached, the pods can be manually deleted by using kubectl. In combination with the command shown above, each detected evicted pod can be deleted in a while loop:
ck@mintp ~ $ kubectl get pods --insecure-skip-tls-verify=true --all-namespaces | grep Evicted | while read namespace pod rest; do kubectl --insecure-skip-tls-verify=true delete pod $pod -n $namespace; done
pod "default-http-backend-5f8666475c-2h5s8" deleted
pod "default-http-backend-5f8666475c-2xb56" deleted
pod "default-http-backend-5f8666475c-56xk9" deleted
pod "default-http-backend-5f8666475c-5kjlc" deleted
[...]
pod "coredns-autoscaler-7768d884b9-vmcll" deleted
pod "coredns-autoscaler-7768d884b9-x2sgx" deleted
pod "coredns-autoscaler-7768d884b9-xqgzr" deleted
pod "coredns-autoscaler-7768d884b9-zdhpc" deleted
No comments yet.

AI AWS Android Ansible Apache Apple Atlassian BSD Backup Bash Bluecoat CMS Chef Cloud Coding Consul Containers CouchDB DB DNS Databases Docker ELK Elasticsearch Filebeat FreeBSD Galera Git GlusterFS Grafana Graphics HAProxy HTML Hacks Hardware Icinga Influx Internet Java KVM Kibana Kodi Kubernetes LVM LXC Linux Logstash Mac Macintosh Mail MariaDB Minio MongoDB Monitoring Multimedia MySQL NFS Nagios Network Nginx OSSEC OTRS Observability Office OpenSearch PHP Perl Personal PostgreSQL PowerDNS Proxmox Proxy Python Rancher Rant Redis Roundcube SSL Samba Seafile Security Shell SmartOS Solaris Surveillance Systemd TLS Tomcat Ubuntu Unix VMware Varnish Virtualization Windows Wireless Wordpress Wyse ZFS Znuny Zoneminder