
Recently we've come along a very strange problem: A DNS master slave replication, using PowerDNS, stopped working. The slave DNS servers still showed old records and even the SOA serial was older than on the master DNS server.
Logs on the slave servers clearly showed that there is a newer SOA serial available on the master:
Aug 18 14:52:03 dnsslave pdns_server[30549]: 4 slave domains need checking, 0 queued for AXFR
Aug 18 14:52:03 dnsslave pdns_server[30549]: Received serial number updates for 4 zones, had 0 timeouts
Aug 18 14:52:03 dnsslave pdns_server[30549]: Domain 'example.com' is stale, master serial 2020081701, our serial 2020080601
The PowerDNS logs further revealed that a transfer (AXFR) from the master (18.xxx.xxx.xxx) is not possible:
Aug 18 14:52:03 dnsslave pdns_server[30549]: Starting AXFR of 'example.com' from remote 18.xxx.xxx.xxx:53
Aug 18 14:52:03 dnsslave pdns_server[30549]: Unable to AXFR zone 'example.com' from remote '18.xxx.xxx.xxx' (resolver): AXFR chunk error: Server Not Authoritative for zone / Not Authorized
Huh?!
To fully understand how a DNS master slave replication works in PowerDNS, check out this article: PowerDNS Master Slave DNS Replication with MySQL backend. This article also explains the difference between different replication modes and how to set up a master slave replication.
But in short, there are a couple of minimum configurations to make a master slave replication work:
Using this knowledge, the configurations of both master and slaves were verified but everything was configured correctly:
Why then would the transfer not work anymore all of a sudden?
In this particular setup, the PowerDNS master is running on a EC2 instance in AWS. In case the availability zone of this EC2 instance is down, or the instance itself has an issue, a second EC2 instance with a "read only" PowerDNS setup was created. The PowerDNS backend of the second EC2 instance is running a MySQL slave of the primary instance, allowing to hold the same data as the primary instance.
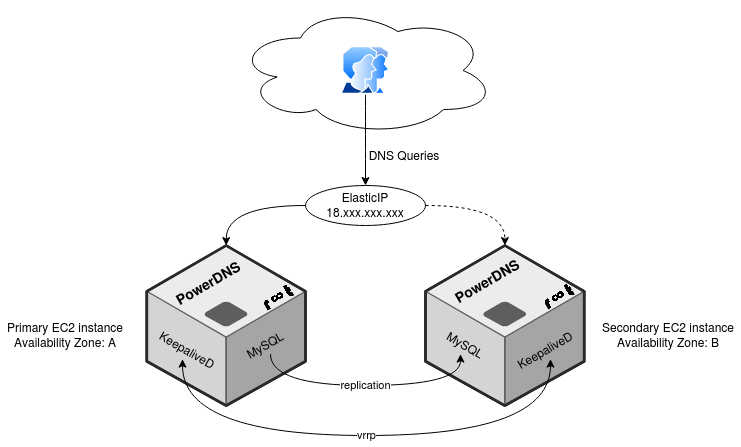
To be able to "balance the public IP" over to the secondary EC2 instance, an Elastic IP was configured. To do an automatic failover of this Elastic IP, Keepalived is used in a MASTER/BACKUP setup. But instead of using a virtual IP address (which would not work with an Elastic IP), a local shell script would be executed. This shell script connects to the AWS API and re-assigns the Elastic IP to the current VRRP master.
With this knowledge in mind, the troubleshooting could proceed.
To be able to see what's happening "live" in the logs, a DNS notify was manually triggered on the master server. This should inform all the slaves (or more correctly: all the nameservers behind a NS record for this zone) of the used zone about changes:
root@dnsmaster:~# pdns_control notify example.com
One particular log entry looked very intriguing on the DNS slave server:
Aug 18 15:18:54 dnsslave pdns_server[14458]: Received NOTIFY for example.com from 54.93.xxx.xxx which is not a master
Where does 54.93.xxx.xxx come from? That's not the static Elastic IP used by the master...
Back on the DNS master on AWS, the outgoing (SNAT) IP address was verified using curl:
root@dnsmaster:~# curl ifconfig.co
54.93.xxx.xxx
The puzzle pieces slowly came together! The primary EC2 instance did not use the Elastic IP as SNAT/outgoing IP address anymore! After the keepalived script was executed, the Elastic IP was re-assigned again:
root@dnsmaster:/etc/keepalived# ./master.sh
{
"AssociationId": "eipassoc-03fxxxxxxxxxxxxxx"
}
And the SNAT IP address went back to the Elastic IP:
root@dnsmaster:~# curl ifconfig.co
18.xxx.xxx.xxx
Shortly after this, DNS transfers automatically started working again on the DNS slave servers:
Aug 18 15:23:18 dnsslave pdns_server[14458]: AXFR started for 'example.com'
Aug 18 15:23:18 dnsslave pdns_server[14458]: AXFR of 'example.com' from remote 18.xxx.xxx.xxx:53 done
Aug 18 15:23:18 dnsslave pdns_server[14458]: Backend transaction started for 'example.com' storage
Aug 18 15:23:18 dnsslave pdns_server[14458]: AXFR done for 'example.com', zone committed with serial number 2020081801
According to our monitoring, the Elastic IP was balanced over to the secondary EC2 instance. This can nicely be seen by looking at the number of DNS queries on the primary vs. the secondary EC2 instance:
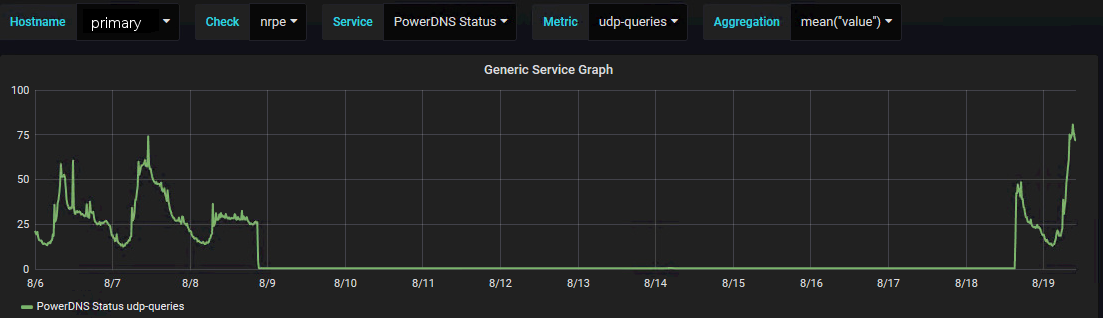
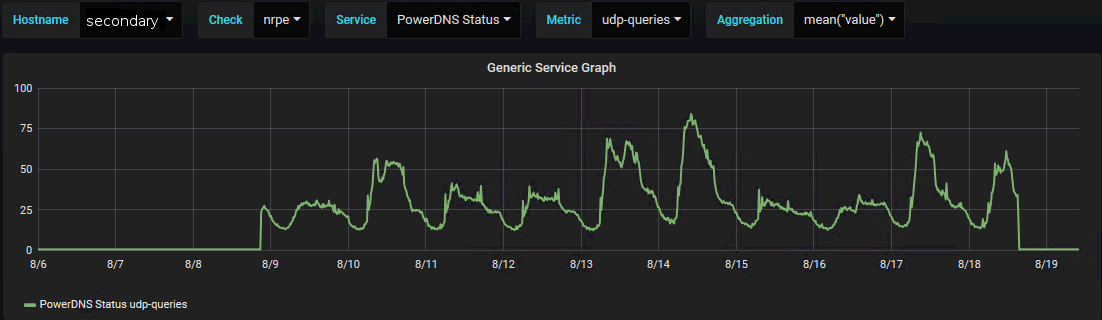
The good news: The Elastic IP failover did not cause any downtime (yet if it would have, monitoring would have alerted immediately). But the question remains: What did trigger the failover?
According to the graph, the failover happened on August 8th at around 9pm. That's definitely outside of our office hours so a human interaction from one of the administrators can likely be ruled out. Finally the following syslog events were found with journalctl on the primary EC2 instance:
root@dnsmaster:~# journalctl | grep -i keepalived
[...]
Aug 08 21:01:15 dnsmaster Keepalived_vrrp[8947]: VRRP_Instance(VI_1) Received advert with lower priority 102, ours 103, forcing new election
Aug 08 21:01:16 dnsmaster Keepalived_vrrp[8947]: VRRP_Instance(VI_1) Received advert with lower priority 102, ours 103, forcing new election
And on the secondary EC2 instance:
root@dnsmaster2:~# journalctl | grep -i keepalived
Aug 08 21:01:16 dnsmaster2 Keepalived_vrrp[876]: VRRP_Instance(VI_1) Entering MASTER STATE
Aug 08 21:01:16 dnsmaster2 Keepalived_vrrp[876]: Opening script file /etc/keepalived/master.sh
Aug 08 21:01:16 dnsmaster2 Keepalived_vrrp[876]: VRRP_Instance(VI_1) Received advert with higher priority 103, ours 102
Aug 08 21:01:16 dnsmaster2 Keepalived_vrrp[876]: VRRP_Instance(VI_1) Entering BACKUP STATE
So what happened is that the secondary EC2 instance (dnsmaster2) became a master - for no obvious reason. No indication of a failed keepalived health check on the primary instance either. When entering the MASTER STATE, the mentioned shell script is launched which re-assigns the Elastic IP. But when dnsmaster2 switched back to BACKUP state in the same second, the primary instance (dnsmaster) did not switch the state (it did not even change to BACKUP state). Hence the master.sh shell script was not executed and the Elastic IP remained assigned to the secondary EC2 instance.
So the big question is really: Why did KeepaliveD switch the state on the secondary instance but not on the primary? One possibility could be that the network connection between the availability zones stopped working for a very brief moment and the VRRP communication using the internal IPs did not work anymore (also see this question on serverfault). Another hint can also be found in a currently still open issue in the KeepaliveD repository on GitHub (Repeating "Received advert with lower priority 103, ours 104, forcing new election"). Here, the possible explanation points, once again, to a network problem:
The reality is that keepalived, or more specifically VRRP, can only work reliably if the network between the various systems running keepalived is itself reliable, and it appears that intermittent problems of a backup instance becoming master when the master is still running are quite a good way of identifying that there are network problems.
But as this problem occurred inside AWS cloud, it is unfortunately impossible to find out exactly what happened in this second. One just needs to rely and "trust" the cloud in such setups.
By checking the public IP address, as shown above with curl, it can be verified that the Elastic IP is assigned to the primary EC2 instance. This can be used by the monitoring plugin check_http. In this example, check_http makes a request to icanhazip.com (or basically to any other public IP lookup) and checks for the string "18.xxx.xxx.xxx" to identify its own Elastic IP. The check will fail if the string is not found in the response.
root@dnsmaster:~# /usr/lib/nagios/plugins/check_http -H www.icanhazip.com -u / -p 80 -s "18.xxx.xxx.xxx" -w 10 -c 20
HTTP OK: HTTP/1.1 200 OK - 413 bytes in 0.012 second response time |time=0.012308s;10.000000;20.000000;0.000000;21.000000 size=413B;;;0
As soon as the Elastic IP is detached from the primary EC2 instance, this check will fail and alert the administrators in charge.

No comments yet.

AI AWS Android Ansible Apache Apple Atlassian BSD Backup Bash Bluecoat CMS Chef Cloud Coding Consul Containers CouchDB DB DNS Databases Docker ELK Elasticsearch Filebeat FreeBSD Galera Git GlusterFS Grafana Graphics HAProxy HTML Hacks Hardware Icinga Influx Internet Java KVM Kibana Kodi Kubernetes LVM LXC Linux Logstash Mac Macintosh Mail MariaDB Minio MongoDB Monitoring Multimedia MySQL NFS Nagios Network Nginx OSSEC OTRS Observability Office OpenSearch PHP Perl Personal PostgreSQL PowerDNS Proxmox Proxy Python Rancher Rant Redis Roundcube SSL Samba Seafile Security Shell SmartOS Solaris Surveillance Systemd TLS Tomcat Ubuntu Unix VMware Varnish Virtualization Windows Wireless Wordpress Wyse ZFS Znuny Zoneminder