
A new version of check_rancher2, an open source monitoring plugin for Kubernetes clusters managed by SUSE Rancher, is available! Version 1.10.0 handles an important bug when using a newer Kubernetes version in a cluster and adds other enhancements.
In previous Kubernetes versions, the "ComponentStatus" was used to identify issues within a Kubernetes cluster. This was also heavily used by Rancher and even integrated into the (old) user interface in the cluster overview:
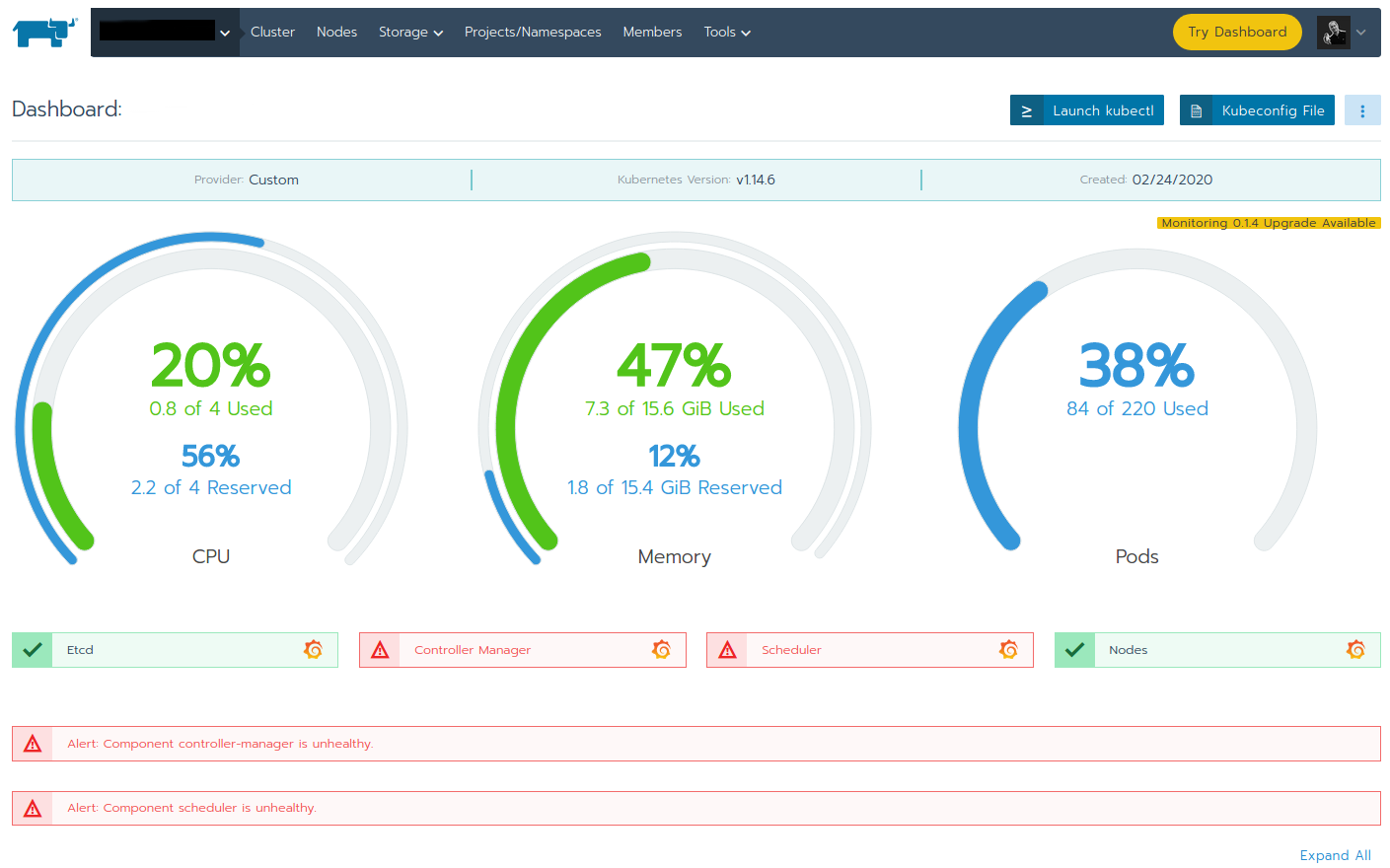
The ComponentStatus not only showed up in the user interface but also in the Rancher API. The check_rancher2 monitoring plugin used the API output and obtained the current statutes from the ComponentStatus block.
However the ComponentStatus health checks were never 100% reliable in the first place (see related article Rancher 2 Kubernetes cluster shows alerts on Controller Manager and Scheduler for a technical deep dive). From that mentioned article:
ComponentStatus health checks of controller-manager and scheduler [...] are not working as they should
With the release of Kubernetes 1.19 the ComponentStatus was marked as deprecated.
Note: A working replacement for ComponentStatus was never announced.
According to the opened issue #35 it seems that the Rancher API removed the ComponentStatus output since Kubernetes version 1.22 or 1.23. Reporter jajla mentioned:
In two steps, I upgraded v1.21 cluster to v1.22, then continued with v1.23.
It's still good on v1.21, but not anymore on v1.23.
To properly handle this, check_rancher2 now tries to parse the ComponentStatus array from the API's JSON output, if the array exists. Otherwise it will silently skip that part.
While working on the issue with the newer Kubernetes versions mentioned above it crossed my mind that an information of the currently used Kubernetes version in a cluster would be really helpful.
Up until release 1.10.0, the output of a single cluster check (using -t cluster -c clusterid) simply showed whether or not the checked cluster is healthy:
$ ./check_rancher2.sh -H rancher2.example.com -U token-xxxxx -P "secret" -S -t cluster -c c-xxxxx
CHECK_RANCHER2 OK - Cluster test is healthy|'cluster_healthy'=1;;;; 'component_errors'=0;;;; 'cpu'=29280;;;;52000 'memory'=29114536832B;;;0;102540578816 'pods'=185;;;;880 'usage_cpu'=56%;;;0;100 'usage_memory'=28%;;;0;100 'usage_pods'=21%;;;0;100
Now with the version 10.0.0, the output also shows the (Rancher installed) Kubernetes version:
$ ./check_rancher2.sh -H rancher2.example.com -U token-xxxxx -P "secret" -S -t cluster -c c-xxxxx
CHECK_RANCHER2 OK - Cluster test (v1.23.10+rke2r1) is healthy|'cluster_healthy'=1;;;; 'component_errors'=0;;;; 'cpu'=29280;;;;52000 'memory'=29114536832B;;;0;102540578816 'pods'=185;;;;880 'usage_cpu'=56%;;;0;100 'usage_memory'=28%;;;0;100 'usage_pods'=21%;;;0;100
In issue #29 a new feature was requested: Ignore statuses in workloads. Ignoring certain statuses was already possible in earlier releases, however only on node checks. The same logic from the node checks was now applied on the workload checks. Certain workload stati can now be ignored.
The following example shows a workload in updating status:
$ ./check_rancher2.sh -H rancher2.example.com -U token-xxxxx -P "secret" -S -t workload -p c-xxxxx:p-xxxxx
CHECK_RANCHER2 WARNING - 1 workload(s) in warning state: Workload efk-filebeat is updating - |'workloads_total'=3;;;; 'workloads_errors'=0;;;; 'workloads_warnings'=1;;;; 'workloads_paused'=0;;;; 'workloads_ignored'=0;;;;
Note: Remember, a workload check requires the project id (-p projectid)
If you want to ignore all workloads with this "updating" status, you can now append -i updating to the command:
$ ./check_rancher2.sh -H rancher2.example.com -U token-xxxxx -P "secret" -S -t workload -p c-xxxxx:p-xxxxx -i updating
CHECK_RANCHER2 OK - All workloads (3) in project c-fctn6:p-2xg6v are healthy/active - Workload efk-filebeat is updating but ignored -|'workloads_total'=3;;;; 'workloads_errors'=0;;;; 'workloads_warnings'=0;;;; 'workloads_paused'=0;;;; 'workloads_ignored'=1;;;;
In this case the monitoring plugin returns status OK, but shows the ignored workload(s) in the output.
The same works of course also for a single workload. Without ignoring the updating status the plugin returns a warning:
$ ./check_rancher2.sh -H rancher.example.com -U token-xxxxx -P "secret" -S -t workload -p c-xxxxx:p-xxxxx -w efk-filebeat
CHECK_RANCHER2 WARNING - Workload efk-filebeat is updating|'workload_active'=0;;;; 'workload_error'=0;;;; 'workload_warning'=1;;;; 'workload_ignored'=0;;;;
Again, append -i updating and the plugin now returns OK (but hints that the status was ignored):
$ ./check_rancher2.sh -H rancher.example.com -U token-xxxxx -P "secret" -S -t workload -p c-xxxxx:p-xxxxx -w efk-filebeat -i updating
CHECK_RANCHER2 OK - Workload efk-filebeat is updating but ignored|'workload_active'=0;;;; 'workload_error'=0;;;; 'workload_warning'=1;;;; 'workload_ignored'=1;;;;
Important note: If you use the ignore parameter (-i) on the workload check, you need to be sure what you're doing. A workload which remains in updating state over a long time is an important indicator that something's not right with that deployment.
No comments yet.

AI AWS Android Ansible Apache Apple Atlassian BSD Backup Bash Bluecoat CMS Chef Cloud Coding Consul Containers CouchDB DB DNS Databases Docker ELK Elasticsearch Filebeat FreeBSD Galera Git GlusterFS Grafana Graphics HAProxy HTML Hacks Hardware Icinga Influx Internet Java KVM Kibana Kodi Kubernetes LVM LXC Linux Logstash Mac Macintosh Mail MariaDB Minio MongoDB Monitoring Multimedia MySQL NFS Nagios Network Nginx OSSEC OTRS Observability Office OpenSearch PHP Perl Personal PostgreSQL PowerDNS Proxmox Proxy Python Rancher Rant Redis Roundcube SSL Samba Seafile Security Shell SmartOS Solaris Surveillance Systemd TLS Tomcat Ubuntu Unix VMware Varnish Virtualization Windows Wireless Wordpress Wyse ZFS Znuny Zoneminder