
Kubernetes is being developed with a high pace. For container infrastructures this means more frequent updates than compared to other platforms (e.g. VMware vsphere). However it brings new features and fixes much faster. But does faster also mean better? Do we risk stability by frequently upgrading the clusters?
Stability can only be attained by inactive matter. - Marie Curie
Note: If the whole Kubernetes management, including upgrades, testing, etc. is too much hassle and effort to you and you just want to enjoy an available Kubernetes cluster to deploy your applications, check out the Private Kubernetes Cloud Infrastructure at Infiniroot!
A recent article (How to upgrade Kubernetes version in a Rancher 2 managed cluster) describes how Kubernetes clusters, managed by Rancher 2, can be upgraded. After a couple of cluster upgrades (from 1.11 to 1.13) this seemed to work pretty well.
However when we decided to upgrade a cluster from 1.13 to 1.14, we were welcomed into Kubernetes hell.
Note: Luckily for us we did that upgrade on a staging cluster so production was not affected, but it still left us with a foul taste.
The upgrade itself seemed to run successfully, having followed all the steps to upgrade Kubernetes, and no error was shown in the Rancher UI. When the Kubernetes version 1.14.6 appeared in the UI, we thought "OK, great!".
Our monitoring didn't see anything wrong; the Rancher environment, monitored by check_rancher2, still worked and returned all workloads as running correctly.
But it didn't take long until the developers came running.
It turned out that since the upgrade to Kubernetes 1.14, all DNS queries/resolutions failed from within the containers.
root@container-4d67k:/# ping google.com
ping: google.com: Temporary failure in name resolution
This applied to both internal DNS records (defined as service in "Service Discovery") and external (real) DNS records. The applications, needing DNS to connect to external services as databases, started to fail. We saw a lot of crash events logged:
E0910 12:57:38.463326 1878 pod_workers.go:190] Error syncing pod 9481d351-d3c8-11e9-823c-0050568d2805 ("service-wx56s_gamma(9481d351-d3c8-11e9-823c-0050568d2805)"), skipping: failed to "StartContainer" for "service" with CrashLoopBackOff: "Back-off 2m40s restarting failed container=service pod=service-wx56s_gamma(9481d351-d3c8-11e9-823c-0050568d2805)"
By further analyzing the logs (all collected centrally in an ELK) we saw that since the upgrade, the number of errors in the cluster sharply increased:
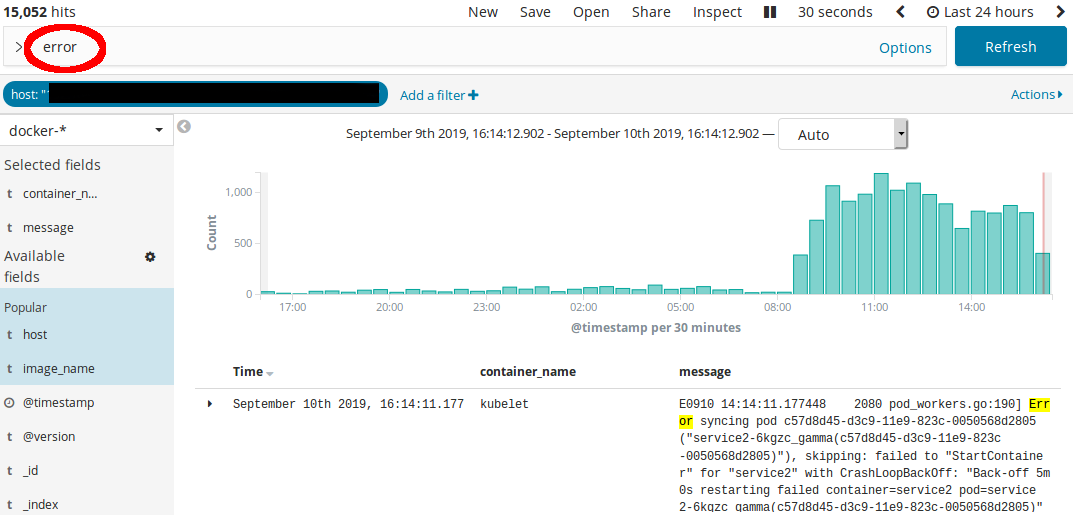
But why would all of a sudden DNS not work anymore?
The Rancher documentation holds a document to troubleshoot DNS issues. But we quickly found out that this document only applies if there are actually DNS services running. It turned out, that our newly upgraded Kubernetes 1.14 cluster did not run any DNS provider services (in the kube-system namespace)!
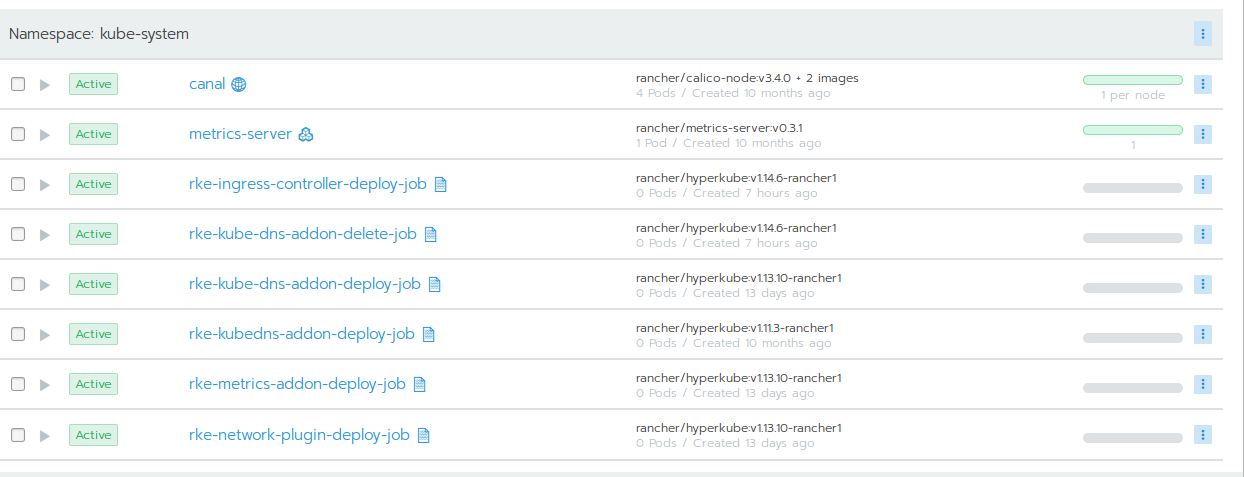
This could be verified using kubectl, too:
ckadm@mintp ~/.kube $ kubectl get pods --all-namespaces | grep kube-system
kube-system canal-fklc2 2/2 Running 4 13d
kube-system canal-fzbrp 2/2 Running 4 13d
kube-system canal-q2qgf 2/2 Running 4 13d
kube-system canal-v89g2 2/2 Running 4 13d
kube-system metrics-server-58bd5dd8d7-hc9rh 1/1 Running 0 72m
There should be a lot more pods in the kube-system. And at least one of either "kube-dns" or "coredns". The latter is the new default DNS service provider starting with Kubernetes 1.14 and Rancher >= 2.2.5:

See default DNS provider from the official Rancher documentation.
This means that CoreDNS should have been deployed, but clearly there were no pods. But maybe there at least a config?
ckadm@mintp ~/.kube $ kubectl -n kube-system get configmap coredns -o go-template={{.data.Corefile}}
Error from server (NotFound): configmaps "coredns" not found
Negative. Not even the coredns configmap was created in the cluster.
From another (and working) Kubernetes 1.14 cluster managed by the same Rancher 2 we took the "coredns" workload's YAML configuration and tried to deploy it manually into the kube-system namespace in the defect cluster.
But unfortunately this failed with the following error:
Pods "coredns-bdffbc666-" is forbidden: error looking up service account kube-system/coredns: serviceaccount "coredns" not found
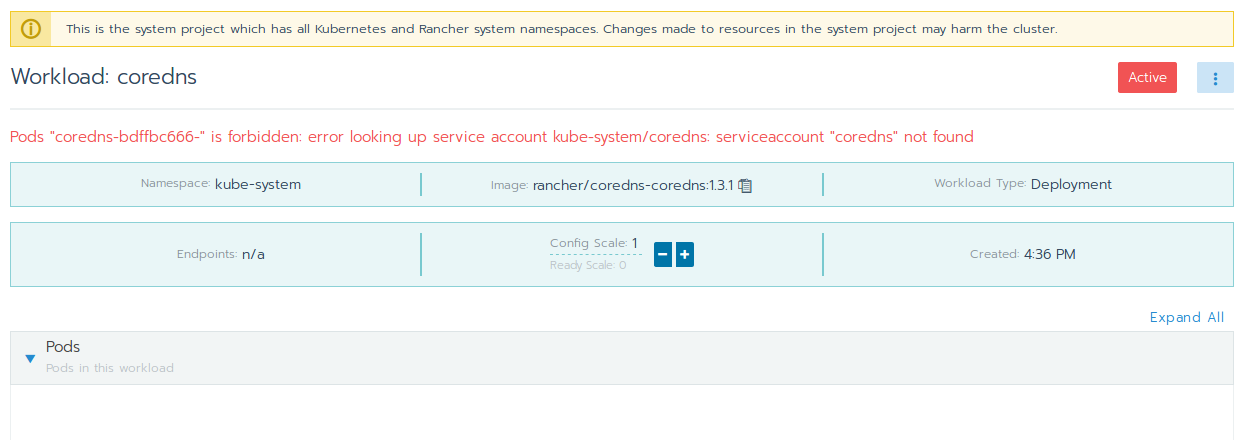
With kubectl it can be verified whether or not the service account for coredns exists or not:
ckadm@mintp ~/.kube $ kubectl get serviceAccounts --all-namespaces | grep dns
ckadm@mintp ~/.kube $
Indeed, no results. Comparing with a working Kubernetes 1.14 cluster:
> kubectl get serviceAccounts --all-namespaces | grep dns
kube-system coredns 1 13d
kube-system coredns-autoscaler 1 13d
kube-system kube-dns 1 307d
kube-system kube-dns-autoscaler 1 307d
It seemed that the coredns deployment during the Kubernetes upgrade completely failed. Not only were no DNS pods created, the cluster configuration was incomplete, too (no configmap, no serviceaccount).
The Kubernetes upgrade is initiated by Rancher itself, as it manages the Kubernetes cluster. The creation and upgrade of a Kubernetes cluster creates provisioning logs, logged by the Rancher server pod (the one with the image rancher/rancher). This pod can be found in the "local" cluster (Rancher itself).
Checking the logs revealed something very interesting:
"September 10th 2019, 08:53:29.104","2019/09/10 06:53:29 [INFO] cluster [c-hpb7s] provisioning: [addons] Executing deploy job rke-network-plugin"
"September 10th 2019, 08:53:29.216","2019/09/10 06:53:29 [INFO] cluster [c-hpb7s] provisioning: [dns] removing DNS provider kube-dns"
"September 10th 2019, 08:54:29.562","2019/09/10 06:54:29 [ERROR] cluster [c-hpb7s] provisioning: Failed to deploy DNS addon execute job for provider coredns: Failed to get job complete status for job rke-kube-dns-addon-delete-job in namespace kube-system"
"September 10th 2019, 08:54:29.576","2019/09/10 06:54:29 [INFO] cluster [c-hpb7s] provisioning: [addons] Setting up Metrics Server"
"September 10th 2019, 08:54:29.592","2019/09/10 06:54:29 [INFO] cluster [c-hpb7s] provisioning: [addons] Saving ConfigMap for addon rke-metrics-addon to Kubernetes"
"September 10th 2019, 08:54:29.612","2019/09/10 06:54:29 [INFO] cluster [c-hpb7s] provisioning: [addons] Successfully saved ConfigMap for addon rke-metrics-addon to Kubernetes"
Obviously the task to deploy coredns failed with an error. However the upgrade continued on the next step (metrics server) instead of doing something - halt the upgrade? try to resolve the error? shout to the admin? just anything, really?
To this point we knew:
The obvious solution would have been to downgrade to the previous Kubernetes version (1.13). However this was not possible because a Kubernetes downgrade through Rancher (RKE) is not supported.
The only available option was to further upgrade the whole cluster to the next Kubernetes version: 1.15. But as of the cluster problem (and still as of this writing), 1.15 is marked as experimental. We decided to give it a shot anyway.
To be honest we doubted that the upgrade in a non-working cluster to Kubernetes 1.15 would work, but to our surprise the upgrade seemed to run through pretty well.
The eyes were especially fixed on the messages related to everything DNS (guess why!). Once the upgrade process was completed, it was time to see if DNS would be working. And the first checks looked good:
ckadm@mintp ~/.kube $ kubectl get serviceAccounts --all-namespaces | grep dns
kube-system coredns 1 88s
kube-system coredns-autoscaler 1 88s
The service account now existed! What about the pods?
ckadm@mintp ~/.kube $ kubectl get pods --all-namespaces | grep kube-system
kube-system canal-2jf4g 2/2 Running 0 2m56s
kube-system canal-l8xvm 2/2 Running 0 3m12s
kube-system canal-rz972 2/2 Running 2 3m35s
kube-system canal-st25h 2/2 Running 0 2m40s
kube-system coredns-5678df9bcc-99xch 1/1 Running 1 2m50s
kube-system coredns-autoscaler-57bc9c9bd-c8sqw 1/1 Running 0 2m50s
kube-system metrics-server-784769f887-6zz2s 1/1 Running 0 2m15s
kube-system rke-coredns-addon-deploy-job-xbqjq 0/1 Completed 0 3m21s
kube-system rke-metrics-addon-deploy-job-cmv8m 0/1 Completed 0 2m46s
kube-system rke-network-plugin-deploy-job-297lv 0/1 Completed 0 3m37s
Good news! The coredns pod was up and running!
What about the application pods? Would they finally be able to resolve DNS?
root@service2-qw7kz:/# ping google.com
PING google.com (172.217.168.14) 56(84) bytes of data.
64 bytes from zrh11s03-in-f14.1e100.net (172.217.168.14): icmp_seq=1 ttl=54 time=2.70 ms
64 bytes from zrh11s03-in-f14.1e100.net (172.217.168.14): icmp_seq=2 ttl=54 time=2.08 ms
64 bytes from zrh11s03-in-f14.1e100.net (172.217.168.14): icmp_seq=3 ttl=54 time=1.98 ms
^C
--- google.com ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2002ms
rtt min/avg/max/mdev = 1.983/2.257/2.708/0.321 ms
Heureka! DNS is back and the applications work again. That would be the solution. Or would it?
The cluster, now running with Kubernetes 1.15, went through a process of testing. And it turned out that as soon as a workload was upgraded, the communication through the Ingress Loadbalancer would fail. Updating the load balancer's rules forced a new nginx.conf configuration file in the nginx-ingress-controller pods, pointing to an internal service ingress-516586323564684964. Although this internal service was correctly configured in the Nginx ingress, the internal DNS records (which can be seen in Service Discovery) were missing. We pointed this out in a Rancher GitHub issue.
From the point of view of the Nginx ingress, this is a non-existant upstream, therefore returning 503 to all requests.
We could have manually created the relevant services in "Service Discovery" using the exact ingress-id name used by the Ingress Loadbalancer. However what's the point of manually creating configs when the whole point of a Kubernetes cluster is automation (by a high degree at least)?
We knew at the beginning already that if the Kubernetes cluster could not be fixed, we would simply create a new cluster from scratch and deploy all the workloads in this new cluster. And that's what we did. A new node was spun up and was ready in a couple of minutes and a new cluster (using Kubernetes 1.14! yes, we dared it!) with a single-node was created in Rancher. The namespace was exported from the old cluster and imported into the new and the workloads began to deploy.
Because in our architecture we use load balancers in front of the Kubernetes clusters, the traffic was simply switched to the new cluster. The applications worked again.
Once the whole cluster was deemed working correctly, the nodes from the broken cluster were reset (see how to reset (clean up) a Rancher Docker Host) and added as additional nodes into the new cluster.
Knowledge. And this is worth much. We learned about the DNS providers, Kubernetes config maps and service accounts and how Rancher creates the Nginx Ingress config. And last but not least we now have a procedure to quickly create a new cluster from scratch, "migrating" the workloads from the old into the new cluster.
Something however is still unknown at this moment: The reason why the Rancher initiated Kubernetes upgrade, especially the coredns deployment task, failed and why it was not fixed. It may turn out to be a bug in Rancher, the Rancher team was informed about that incident. If we ever get to know the reason, we will update this article.
We decided to share this knowledge to give insights into our working methods and to help fellow DevOps struggling with the same or similar issues.
This is an update one day after the initial article. Once the new cluster running Kubernetes 1.14 was deemed OK, all the original nodes were added again. This also included a remote node running in AWS with the roles "etcd" and "control plane", which serves as man-in-the-middle in case of split-brain situations between the two data centers. As soon as this node was added, DNS issues happened again - even with a correctly deployed coredns service. This could (this time) be verified using the DNS troubleshooting steps:
ckadm@mintp ~ $ kubectl run -it --rm --restart=Never busybox --image=busybox:1.28 -- nslookup kubernetes.default
If you don't see a command prompt, try pressing enter.
Address 1: 10.43.0.10
pod "busybox" deleted
pod default/busybox terminated (Error)
ckadm@mintp ~ $ kubectl run -it --rm --restart=Never busybox --image=busybox:1.28 -- nslookup www.google.com
If you don't see a command prompt, try pressing enter.
Address 1: 10.43.0.10
nslookup: can't resolve 'www.google.com'
pod "busybox" deleted
pod default/busybox terminated (Error)
Both internal and external resolutions failed.
As we were now able to pinpoint the exact timing when DNS started to fail again, we expected a communication problem between the local and the remote node. And indeed, once all tcp and udp ports were enabled in both directions between the cluster nodes, DNS worked again.
Interestingly the incoming ports, which were defined in a AWS security group, all worked fine with Kubernetes 1.13. But since Kubernetes 1.14 additional communication ports seem to be used. An overview of the port requirements is described in the Rancher documentation, but a new Kubernetes version may use different/additional ports again.
No comments yet.

AWS Android Ansible Apache Apple Atlassian BSD Backup Bash Bluecoat CMS Chef Cloud Coding Consul Containers CouchDB DB DNS Database Databases Docker ELK Elasticsearch Filebeat FreeBSD Galera Git GlusterFS Grafana Graphics HAProxy HTML Hacks Hardware Icinga Influx Internet Java KVM Kibana Kodi Kubernetes LVM LXC Linux Logstash Mac Macintosh Mail MariaDB Minio MongoDB Monitoring Multimedia MySQL NFS Nagios Network Nginx OSSEC OTRS Observability Office OpenSearch PGSQL PHP Perl Personal PostgreSQL Postgres PowerDNS Proxmox Proxy Python Rancher Rant Redis Roundcube SSL Samba Seafile Security Shell SmartOS Solaris Surveillance Systemd TLS Tomcat Ubuntu Unix VMWare VMware Varnish Virtualization Windows Wireless Wordpress Wyse ZFS Zoneminder