
A new version of check_zpools, an open source monitoring plugin for ZFS Pools, is available.
The latest version (2026-07-22) contains several bug fixes and implements an important new feature to detect failed disks.
The new release contains a couple of bug fixes:
This is something pretty cool. The pull request from Jens contains a couple of changes that is able to identify which drives have failed in a degraded ZFS Pool.
The change also adds multiple performance data (metrics) to the plugin's output, which can then be parsed for creating visual graphs.
In order to obtain the additional information, check_zpools depends on the JSON output of zpool status, which can be shown using the -j parameter.
The plugin launches this command automatically in the background, if the jq command is available. jq can be installed using apt install jq on Debian and Ubuntu based distributions or dnf install jq on Enterprise Linux distributions.
However it's important to note that the JSON output of zpool only works with OpenZFS 2.2.2 and later. For Debian this means starting with Debian 13. For Ubuntu LTS this starts with Ubuntu 26.04. The plugin automatically detects, whether or not the command is working. If the json output isn't working, the old plugin output will be shown.
So if you run a fairly recent Linux distribution with a recent version of ZFS, the plugin will check the drive health status and show additional performance data as this:
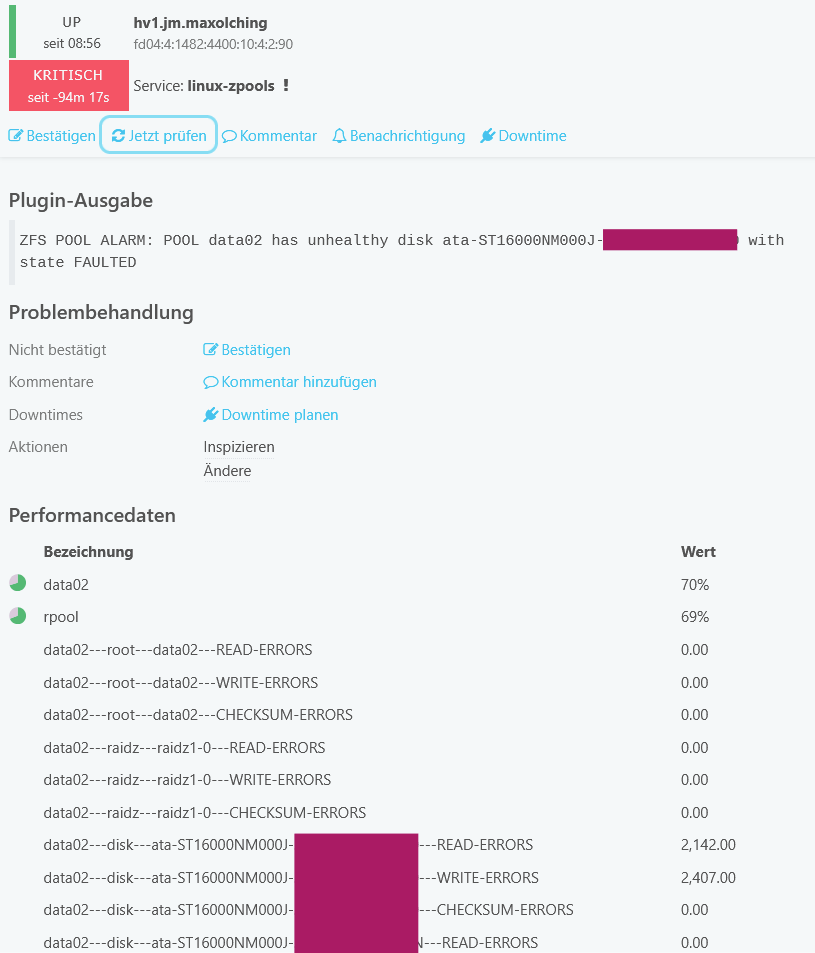
Kudos and thanks to Jens for this nice new feature!

AI AWS Android Ansible Apache Apple Atlassian BSD Backup Bash Bluecoat CMS Chef Cloud Coding Consul Containers CouchDB DB DNS Databases Docker ELK Elasticsearch Filebeat FreeBSD Galera Git GlusterFS Grafana Graphics HAProxy HTML Hacks Hardware Icinga Influx Internet Java KVM Kibana Kodi Kubernetes LVM LXC Linux Logstash Mac Macintosh Mail MariaDB Minio MongoDB Monitoring Multimedia MySQL NFS Nagios Network Nginx OSSEC OTRS Observability Office OpenSearch PHP Perl Personal PostgreSQL PowerDNS Proxmox Proxy Python Rancher Rant Redis Roundcube SSL Samba Seafile Security Shell SmartOS Solaris Surveillance Systemd TLS Tomcat Ubuntu Unix VMware Varnish Virtualization Windows Wireless Wordpress Wyse ZFS Znuny Zoneminder